











【Vertex AI】パルワールドのパルのステータスをOCRして表にしたい

はじまり


どのパルが個体値に関して優秀なんだろうか
同じパルが沢山いる時に気になりました。
Palworld において、パルの個体値って調査ツールなるものが存在しますけど、それをゲーム内で一体ずついちいち確認するのは手間ですし、それをいちいちメモするのは手間です。 Web 上でも調査ツールなるものが存在しますが、そのためにゲーム画面に載っている数値をいちいちブラウザ上で入力するのも一苦労です。
まあ、 Mod が既に存在するかもしれませんが、今回はこれから Palworld 以外にも使えるように、以下のようなツールを作っていきたいと思います。
- Google ドライブにゲーム内のキャラクターのスクショを保存。
- そのスクショを Google Colabolatory から Vertex AI API に送って OCR してもらう。そしてリレーションを作ってもらう。
- その作成したリレーションを Notion ページ内の新しいブロックの中に載せてもらう。
Google ドライブに置くとなると、 Google Apps Script (GAS)でも良さそうですが、今回は Google Colabolatory を利用することにします。その理由としては、 GAS の実行可能時間が短いためです。公式の閾値の掲載によると、およそ6分です。(あと、 Python の SDK を使う方が楽。)

まず、可能なのかどうかを検証。
Vertex AI Studio上で動画をOCR出来るのか?
最初に、動画を OCR させてキャラクターの能力を一覧にすることは可能なのかどうかを検証していきたいと思います。
今回使う動画のイメージとしては、このようなパルのステータス表示を切り替える操作をスクリーンレコードしたものになります。
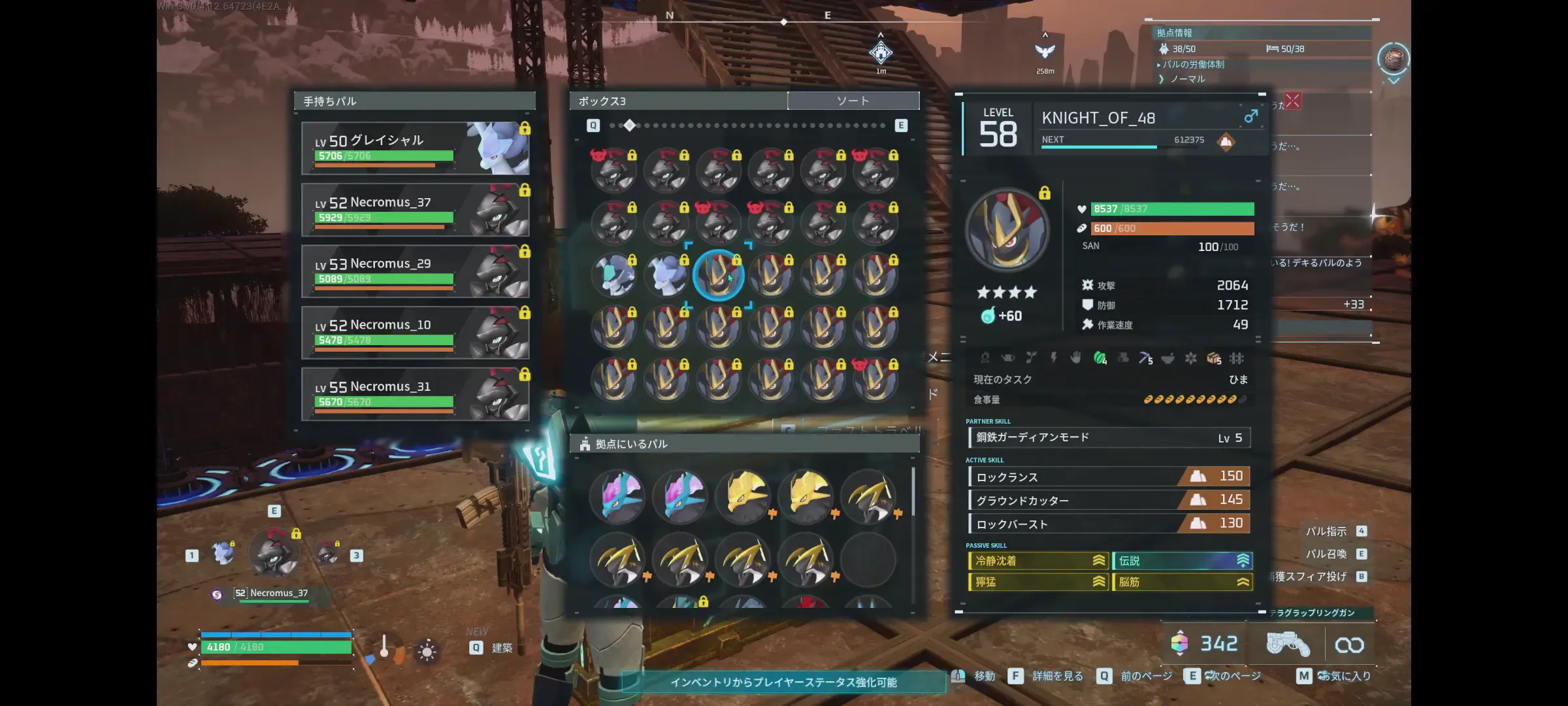
まずは、 Google Cloud の Vertex AI Studio 上で動画をアップロード出来るかどうかを試してみます。
今回 OCR したい動画のサイズは 32MB ぐらいです。アップロード出来ないので、 Google ドライブに配置してみます。
Google ドライブに配置した mp4 ファイルを選択します。
2025-01-07時点では、 Vertex AI などのGeminiを使った動画の OCR には以下の拡張子が利用出来るようです。 Google 公式ページに掲載されていました。
video/mp4video/mpegvideo/movvideo/avivideo/x-flvvideo/mpgvideo/webmvideo/wmvvideo/3gpp

32MB ぐらいの動画を選択したら、「ファイルが大きすぎるため、メディアを追加できません。メディアファイルは 7MB 以下にする必要があります。」と表示されて、添付することが出来ませんでした。
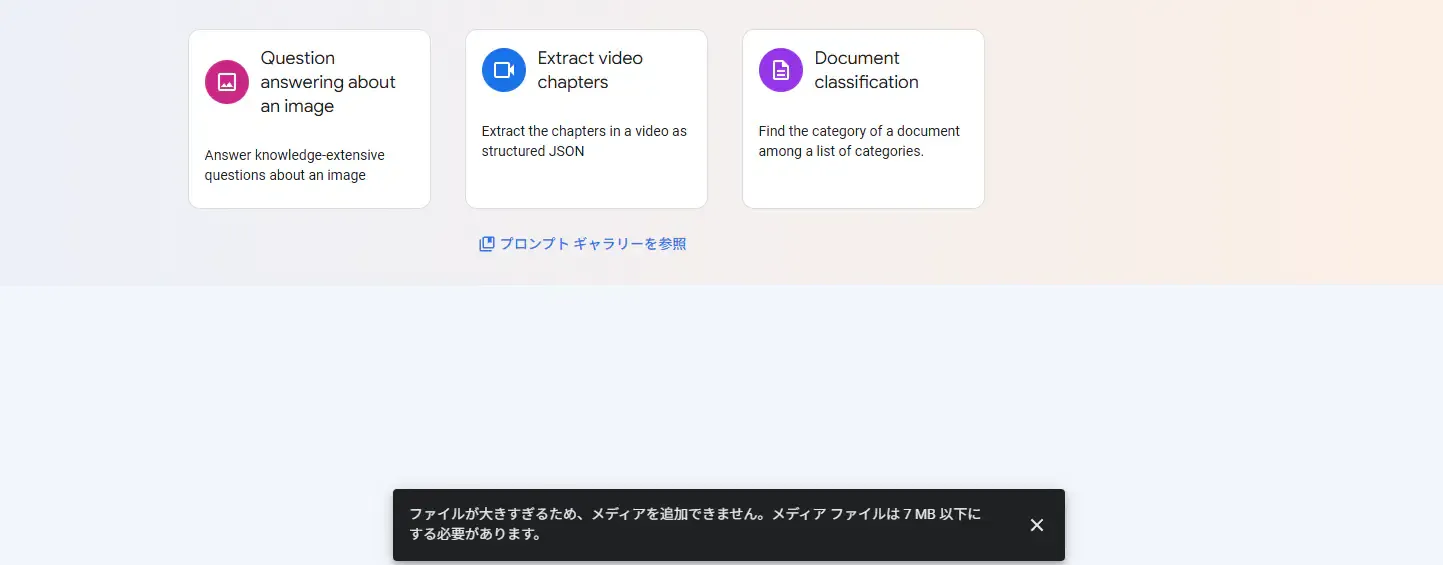
Google AI Studio 上で動画をOCR出来るのか?
次に、 Google AI Studio 上で動画を添付出来るかどうかを確かめてみます。
Vertex AI Studio と同様に、Google ドライブに配置した mp4 ファイルを選択します。
すると、添付することが出来ました。そして、プロンプトに、下記の文面を添えて、生成してもらいました。
この動画から以下のキャラクターのステータスを読み取って、 Markdown のテーブル形式にして。---KNIGHT_OF_01 KNIGHT_OF_02 KNIGHT_OF_03 KNIGHT_OF_04 KNIGHT_OF_05 KNIGHT_OF_06 KNIGHT_OF_07 KNIGHT_OF_08 KNIGHT_OF_09 KNIGHT_OF_10 KNIGHT_OF_11 KNIGHT_OF_12 KNIGHT_OF_13 KNIGHT_OF_14 KNIGHT_OF_15 KNIGHT_OF_16 KNIGHT_OF_17 KNIGHT_OF_18 KNIGHT_OF_19 KNIGHT_OF_20 KNIGHT_OF_21 KNIGHT_OF_22 KNIGHT_OF_23 KNIGHT_OF_24 KNIGHT_OF_25 KNIGHT_OF_26 KNIGHT_OF_27 KNIGHT_OF_28 KNIGHT_OF_29 KNIGHT_OF_30 KNIGHT_OF_31 KNIGHT_OF_32 KNIGHT_OF_33 KNIGHT_OF_34 KNIGHT_OF_35 KNIGHT_OF_36 KNIGHT_OF_37 KNIGHT_OF_38 KNIGHT_OF_39 KNIGHT_OF_40 KNIGHT_OF_41 KNIGHT_OF_42 KNIGHT_OF_43 KNIGHT_OF_44 KNIGHT_OF_45 KNIGHT_OF_46 KNIGHT_OF_47 KNIGHT_OF_48 KNIGHT_OF_49 KNIGHT_OF_50生成に使用したAIモデルは、Gemni 2.0 Flash Experimentalです。
プロンプトを送ると、パル(テラナイト)のステータス情報がリレーション形式で出力されました。
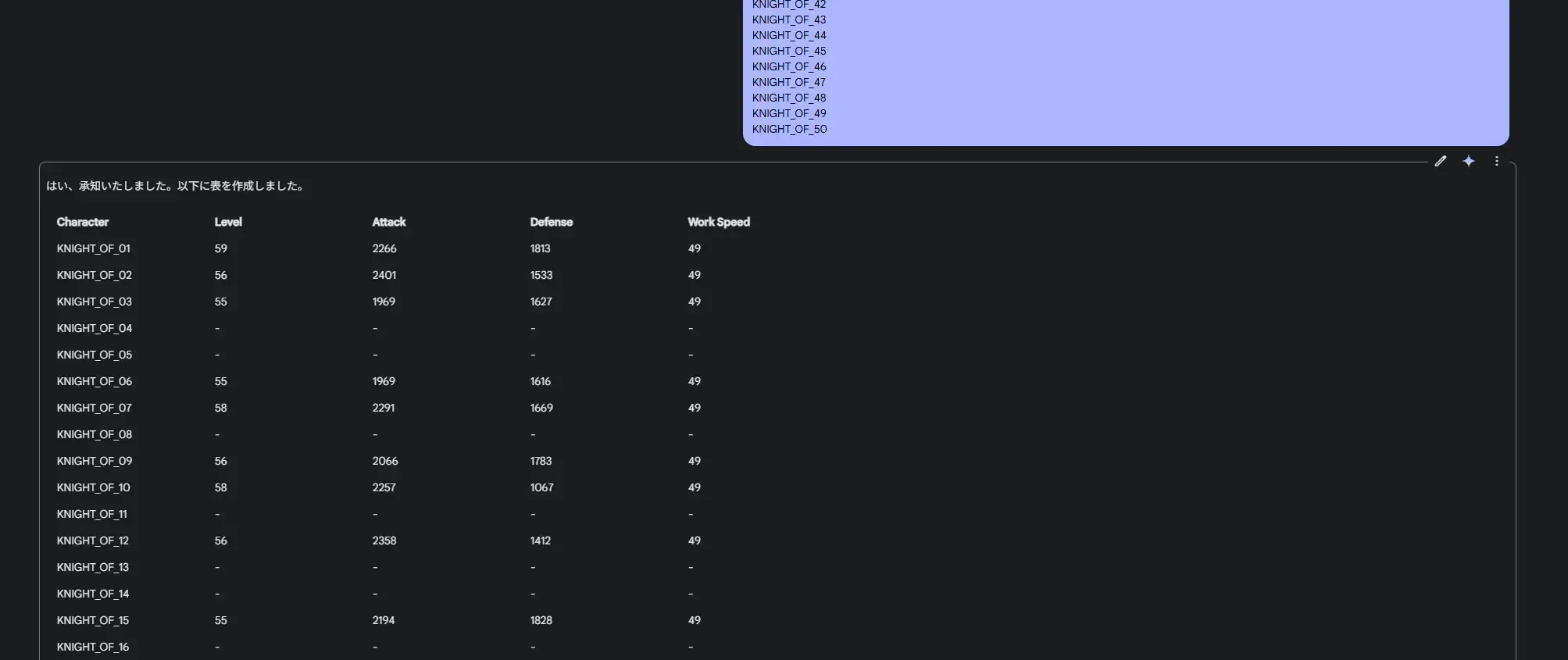
成功です!・・・と言いたいところですが、一部のステータスのパラメータが足りません。
そこで追加のプロンプトとして、下記の内容を送ります。
以下のステータスも書き加えて。---Heart Passive Skill 1 Passive Skill 2 Passive Skill 3 Passive Skill 4しかし・・・、「申し訳ございません。ご要望のステータスは画像から直接読み取ることができないため、表に追加することができません。」と返されてしまいました。動画だとOCRするのはまだ難しいようですね・・・。学習させれば行けなさそうもないですが。

Google AI Studio上で画像をOCR出来るのか?
次に、先程から使っている動画から一体ずつスクショを撮って、その画像をアップロードして生成AIにデータを抽出してもらおうと思います。まあ、今回は 52 体のパルなのでスクショぐらいであれば労力的に問題ないです。
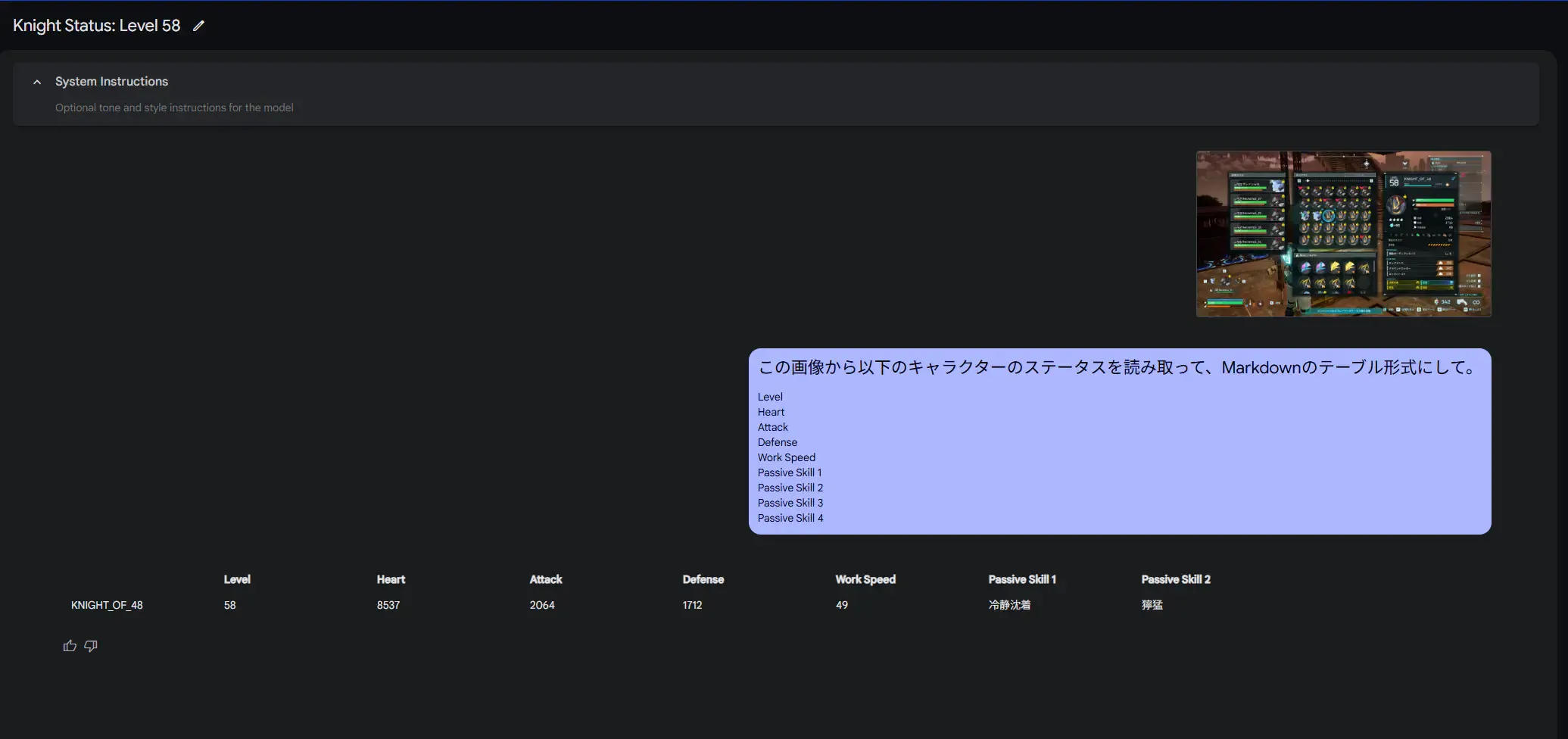
Google AI Studio で、画像をアップロードしてから、下記のプロンプトを与えます。
この画像から以下のキャラクターのステータスを読み取って、Markdownのテーブル形式にして。---Level Heart Attack Defense Work Speed Passive Skill 1 Passive Skill 2 Passive Skill 3 Passive Skill 4しかし、まだ物足りない部分がありました・・・。この後に追加プロンプトも与えましたが、どうしても読み取ることが出来ないステータスがありました。この時のAIモデルも、Gemni 2.0 Flash Experimentalです。
Vertex AI Studio 上で画像をOCR出来るのか?
それでは、 Vertex AI Studio 上で画像の OCR が可能なのかどうかを確かめます。
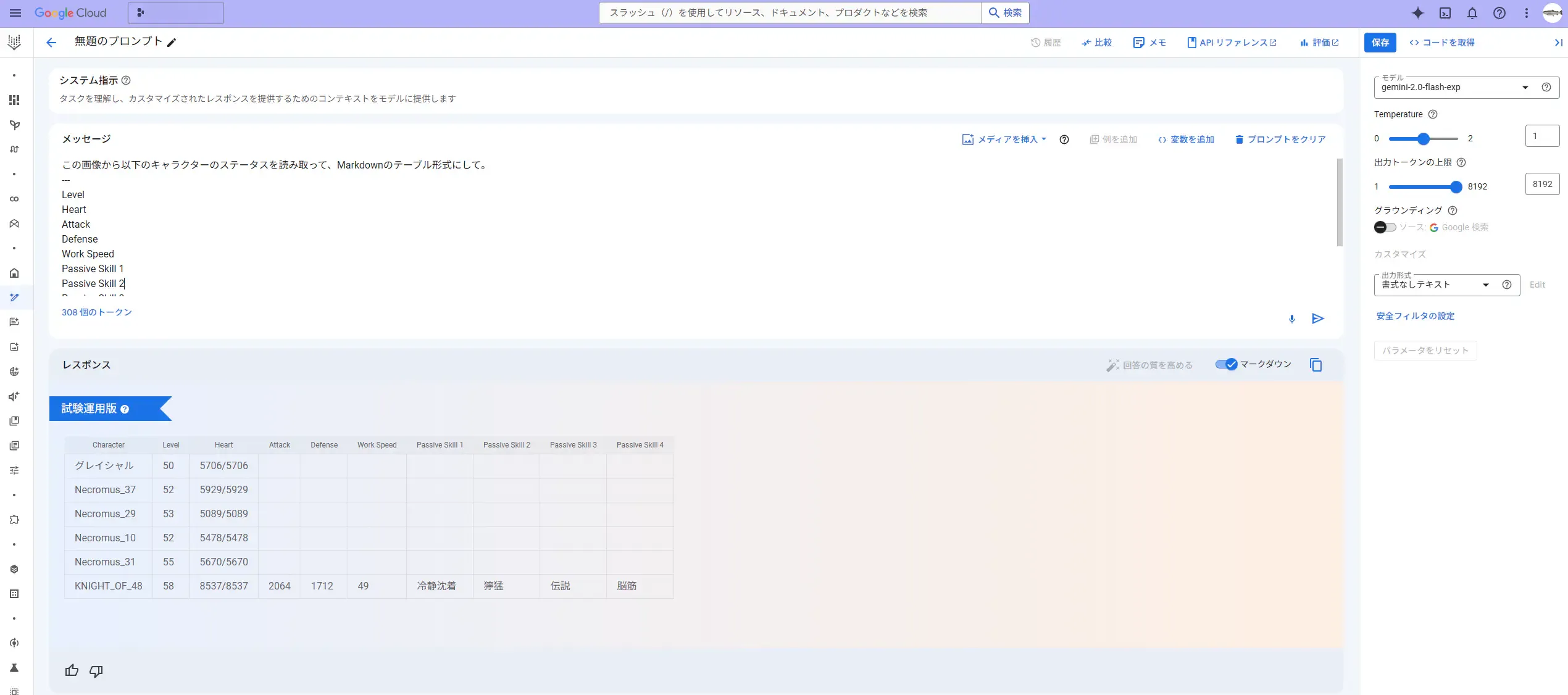
画像は、動画と違って問題なくアップロードできました。下記の文面を記載して送りました。
この画像から以下のキャラクターのステータスを読み取って、Markdownのテーブル形式にして。---Level Heart Attack Defense Work Speed Passive Skill 1 Passive Skill 2 Passive Skill 3 Passive Skill 4すると、今回は上手く行きました。こちらが指示したパラメータを全て読み取ってリレーション形式でまとめることが出来ています。この時に生成に使用したAIモデルも、gemini-2.0-flash-expです。Gemni 2.0 Flash Experimentalと同じものです。
なぜ同じモデルで結果が異なるのかは分かりませんが、プロンプト内のトークンの順番は違ったので、そこが関係あるかもしれません。Google AI Studio上では、画像を示すトークンが指示文の前に来ていましたが、 Vertex AI Studio 上では、画像を示すトークンを指示文の後ろに配置して、成功することが出来ました。うーんまあ、この事は実際に API 経由でプロンプトする際の参考にしておくことします。
Googleドライブにゲーム内のキャラクターのスクショを保存。
それでは、画像を OCR することが可能なことは分かったので、実際に Gemini API を叩いて、 Notion API でデータを載せるところまで作ってみたいと思います。
まずは Gemini にプロンプトするための画像のトークンを作る部分を作ります。 Google ドライブにはこのようにパルのステータスが映っているスクショをアップロードしておきます。
Google Colabolatoryで一括OCR処理を実装する。
Pythonコードを作る。
そして Google Colabolatory を使って、 OCR 処理の部分まで組み立てます。
まずは、以下の処理で Vertex AI のGemini APIを使って OCR することが出来ます。
from google import genaifrom google.genai import typesimport base64from google.colab import userdata
def image_file_to_base64(file_path): with open(file_path, "rb") as image_file: data = base64.b64encode(image_file.read())
return data.decode('utf-8')
def generate_chunks(img_path: str): PROJECT_ID = userdata.get('gcloud_project_id') # like env in Google Colab LOCATION = userdata.get('gcloud_location') # like env in Google Colab client = genai.Client( vertexai=True, project=PROJECT_ID, location=LOCATION )
b64_image =image_file_to_base64(img_path) image1 = types.Part.from_bytes( data=base64.b64decode("""UklGRha......eqQAAA="""), mime_type="image/webp", ) image1 = types.Part.from_bytes( data=base64.b64decode(b64_image), mime_type="image/webp", ) textsi_1 = """以下のカラムを持ったテーブル形式で出力して。---Character NameLevelHeartAttackDefenseWork SpeedPassive Skill 1Passive Skill 2Passive Skill 3Passive Skill 4""" prompt = """この画像からキャラクターのステータスを読み取って、Markdownのテーブル形式にして。"""
model = "gemini-2.0-flash-exp" contents = [ types.Content( role="user", parts=[ image1, types.Part.from_text(prompt) ] ) ] generate_content_config = types.GenerateContentConfig( temperature = 1, top_p = 0.95, max_output_tokens = 8192, response_modalities = ["TEXT"], safety_settings = [types.SafetySetting( category="HARM_CATEGORY_HATE_SPEECH", threshold="OFF" ),types.SafetySetting( category="HARM_CATEGORY_DANGEROUS_CONTENT", threshold="OFF" ),types.SafetySetting( category="HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold="OFF" ),types.SafetySetting( category="HARM_CATEGORY_HARASSMENT", threshold="OFF" )], system_instruction=[types.Part.from_text(textsi_1)], )
chunks = [] for chunk in client.models.generate_content_stream( model = model, contents = contents, config = generate_content_config, ): chunks.append(chunk) print(chunk, end="")
return chunks
images = [ "/content/drive/MyDrive/tmp/Screenshot_20250107-045338.webp"]parts = []md_tables = []for img_file_path in images: chunks = generate_chunks(img_file_path) print(chunks) for i in range(len(chunks)): print(chunks[i].candidates[0].content.parts[0].text) parts.append(chunks[i].candidates[0].content.parts[0].text) md_tables.append("".join(parts))print("--------------------------------------\n")print(md_tables)Googleドライブをマウントする。
そしたら、 Google Colabolatory から Google ドライブのファイルにアクセス出来るようにします。
Google Colabolator yのフォルダボタンから Google ドライブをマウントします。
Google ドライブをマウントすると、ずらーっとフォルダが表示されますので、今回 OCR に使用するフォルダを開いて、画像の縦三点リーダーからCopy pathでパスを取得してコードに貼り付けます。(先程掲載したコードのimagesに該当。)
認証を完了させる。
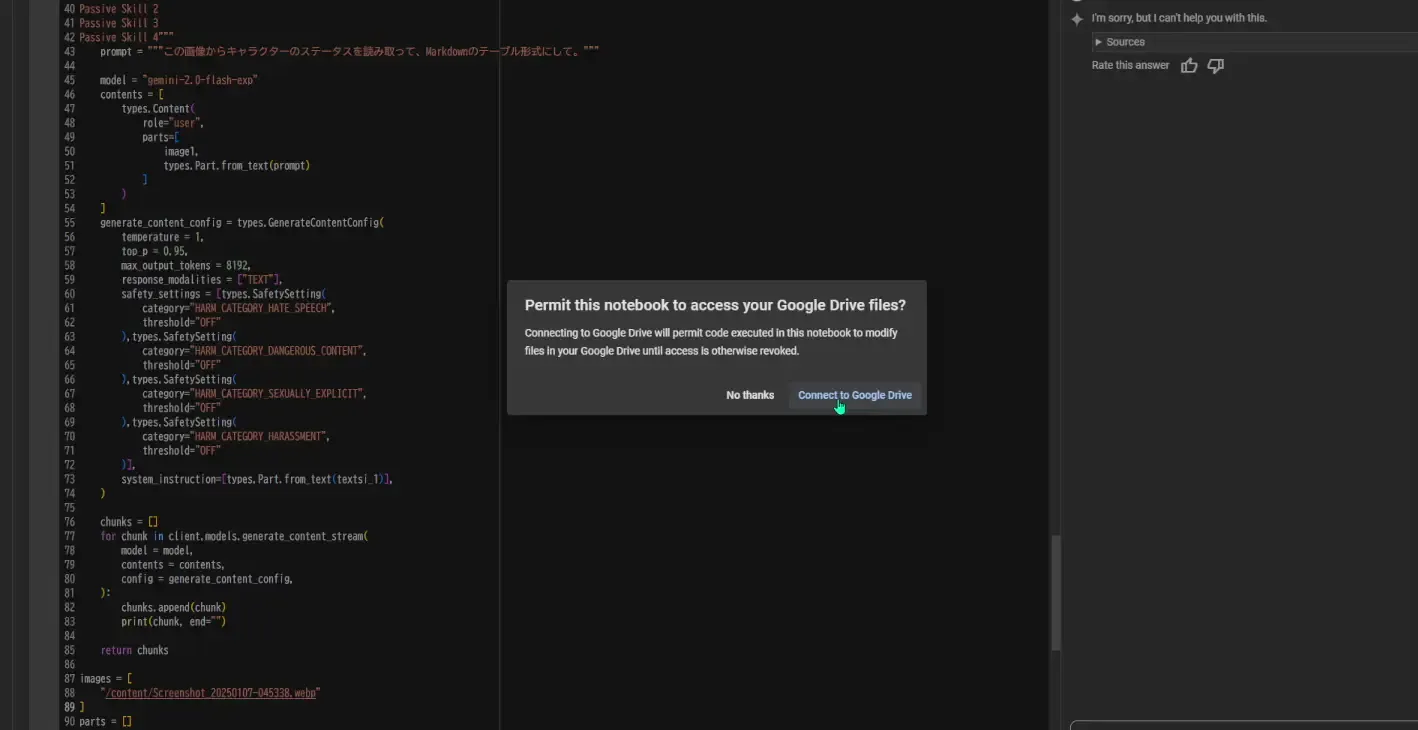
これではまだ Vertex AI の API は利用できません。認証を済ませる必要があります。
Google Cloud コンソール上で Vertex AI の自由形式の画面を表示すると、コードを取得できるボタンがあるので、そこをクリックすると、シェルから Vertex AI API の認証を行うためのコマンドを確認することが出来ます。
pip install --upgrade google-cloud-aiplatformgcloud auth application-default login今回使うのは Google Colabolatory ですので、以下のコマンドでノートブック上に Shell を実行します。
!pip install --upgrade google-cloud-aiplatform!gcloud auth application-default login上記のgcloudコマンドを実行すると、 OAuth2 の認証における認可用URLが発行されるので、その URL をブラウザで叩いて、認可してもらいます。認可されると、アクセスコードが以下のページに貼られているのでそのコードを先程gcloud authを実行したシェル上で入力します。( Google Colabolatory の場合、以下のページを開けていればアクセスコードを入力出来るかと思います。)
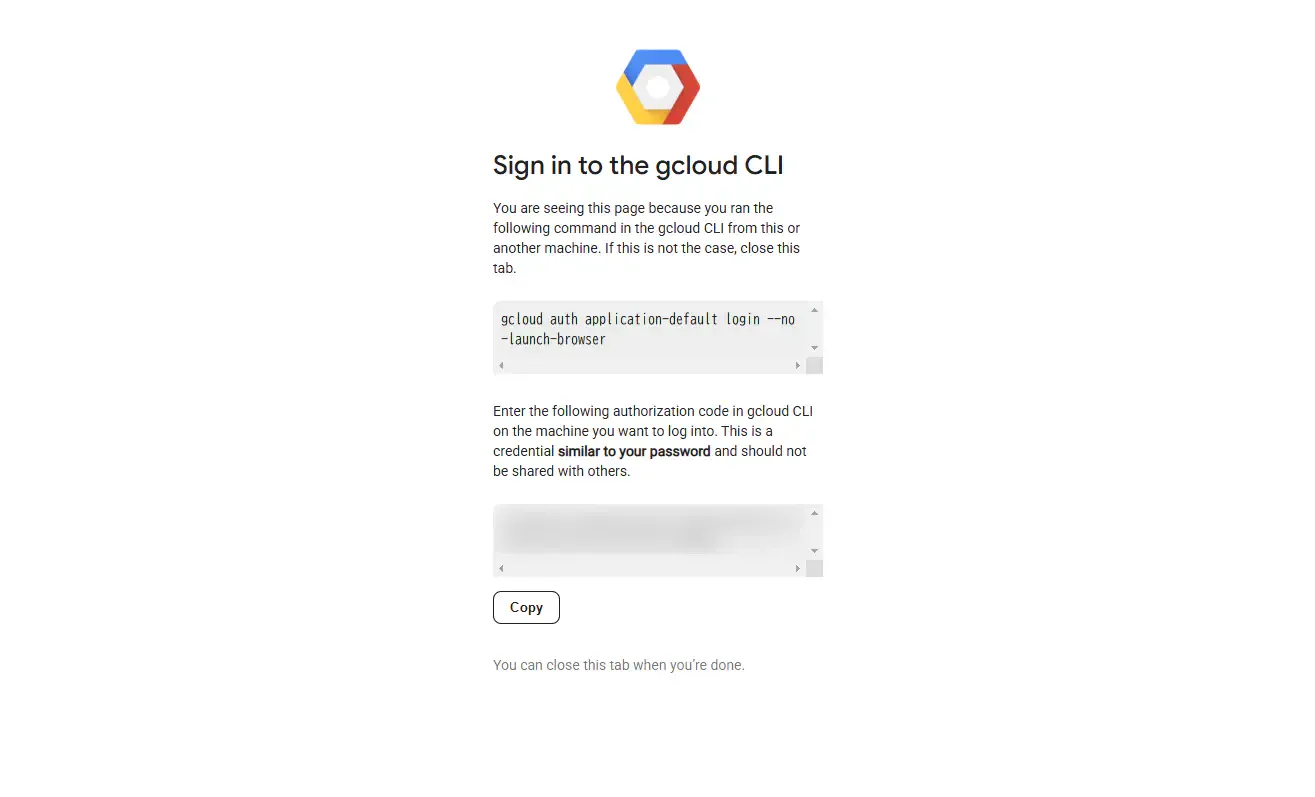
アクセスコードを入力すると、また別のgcloudコマンドで任意の Google Cloud プロジェクトをクォータプロジェクトとして登録しろという指令が出てきたので、そのコマンドをシェル上で叩いて登録します。既に Google Cloud プロジェクトを登録してあれば不要かもしれません。
!gcloud auth application-default set-quota-project <project-id>そのクォータプロジェクトを登録するためのコマンドについては、こちらに公式の解説がありました。
これで数分待てば、認証が完了していると思います。認証作業が完了すると、サービスアカウントの JSON ファイルも出力されるのでプライベートな場所で保管しておきます。
OCRを実行するのだが・・・。
認証も済んだので、 Vertex AI API による OCR を実行していきます。ちゃんと実行できれば、以下のように Gemini から返ってきたものらしき生成内容を表示したり出来るようになりますね。今回検証に使用しているテラナイトのパッシブスキルが画像の中から取得できていることが確認できます。
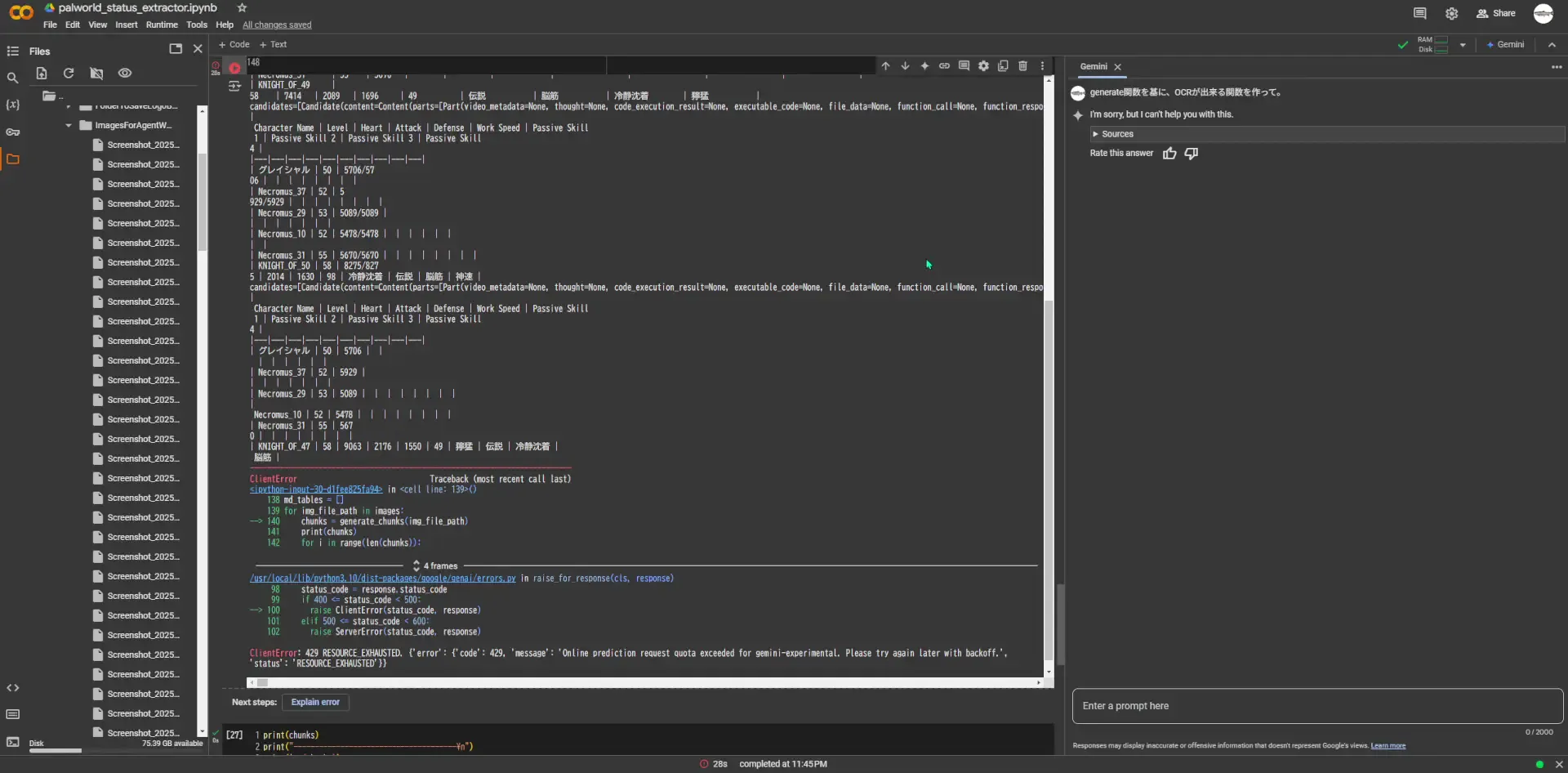
しかし、あれっ・・・。
なんかエラーで止まっている・・・。
ClientError: 429 RESOURCE_EXHAUSTED. {‘error’: {‘code’: 429, ‘message’: ‘Online prediction request quota exceeded for gemini-experimental. Please try again later with backoff.’, ‘status’: ‘RESOURCE_EXHAUSTED’}}
そうです、この時に使った AI モデルはgemini-2.0-flash-expだったのですが、リクエスト頻度が細かすぎると利用制限の閾値に達してしまうようです。
なので、time.sleep(10)とかをリクエストごとに入れてみたりしたのですが、それでもgemini-2.0-flash-expでは相変わらず429 RESOURCE_EXHAUSTED.が表示されて画像の OCR が 10 件も進まないで処理が止まってしまいました。
それではそうですね・・・。AIモデルも変えるしかない・・・?
「gemini-1.5-flash-002」は如実に力不足。
というわけで、 AI モデルをgemini-1.5-flash-002に変えてリトライです。
しかし、 OCR 処理を進めていくと不穏な出力が途中で垣間見られます・・・。
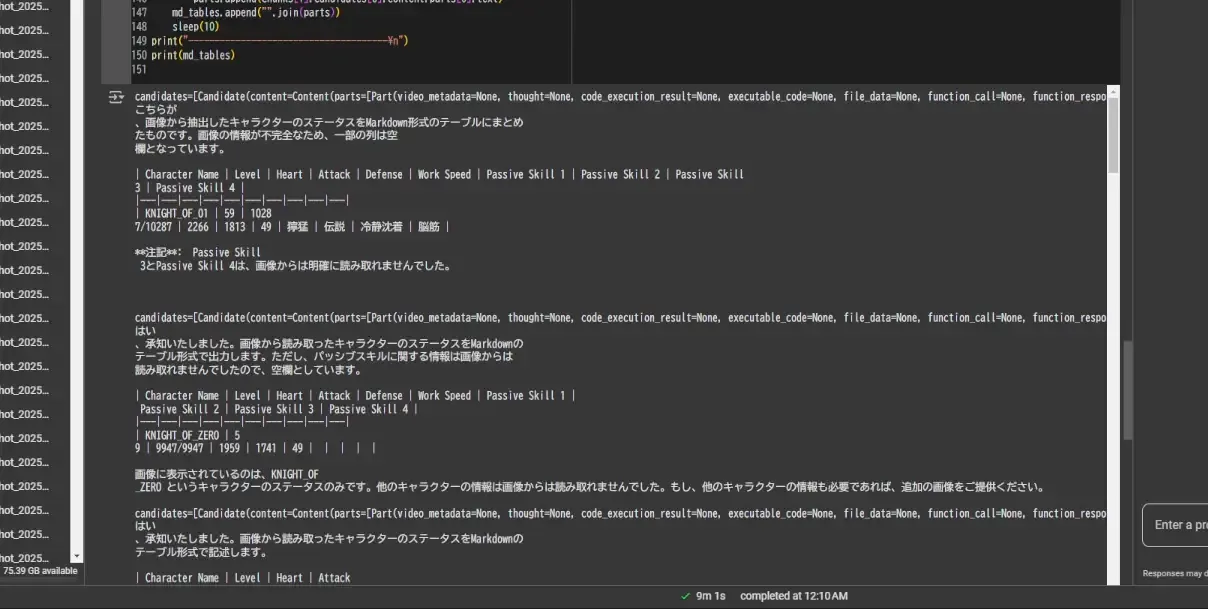
「Passive Skill 3とPassive Skill 4は、画像から明確に読み取れませんでした。」・・・?
うーん、gemini-2.0-flash-expだったら読み取れないなんてことは起きなかったのに・・・。
gemini-1.5-flash-002だと今回の OCR 処理を任せるには力不足が否めませんね・・・。
というわけで次は、gemini-1.5-pro-002に任せてみることにしました。

フム、なんか補足やら解説やらが余計ですが、それはプロンプトによって抑制することは出来るでしょう。
gemini-1.5-pro-002なら、 OCR 処理は上手く行けそうです。
生成したMarkdownをNotionに貼り付ける
それでは、gemini-1.5-pro-002に Markdown のテーブル形式でパルのステータスの表を生成してもらったので、そのテーブルを Notion に貼り付けて、リレーションにしたいと思います。
実際に Notion に貼り付けてみるとこんな感じです。プロンプトから生成したリレーションをさらに ChatGPT にまとめてもらった結果を Notion に貼り付けました。これで加工できそうな形にはなっていそう。
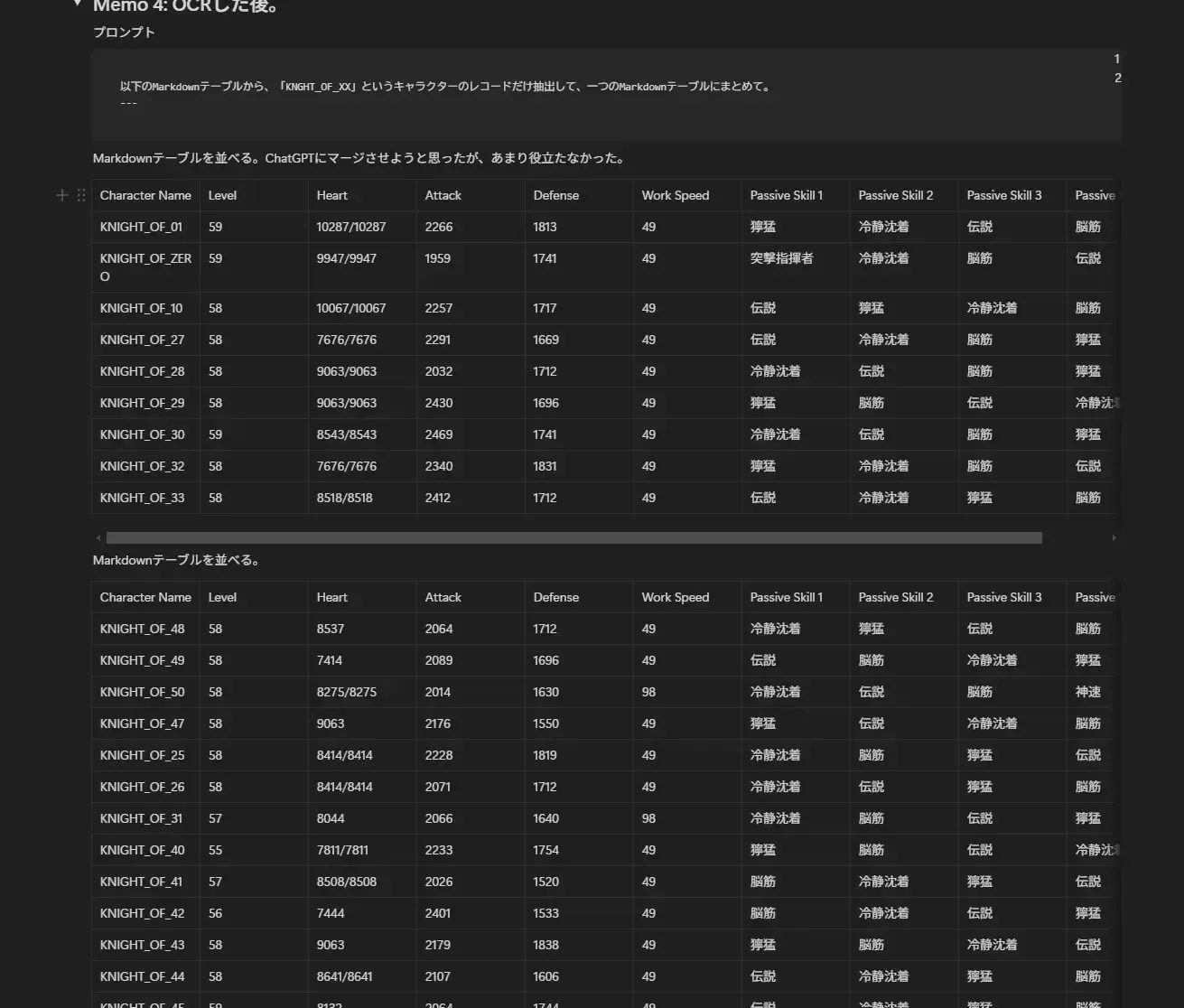
そして少しスプレッドシートで編集して・・・、
ChatGPT がまとめたテーブルを編集した結果はこんな感じです。4匹分のパルが漏れていますね・・・。たぶん、 ChatGPT が漏らしたな・・・? まだまだですね・・・。(ちなみに使ったモデルはGPT-4oです。)
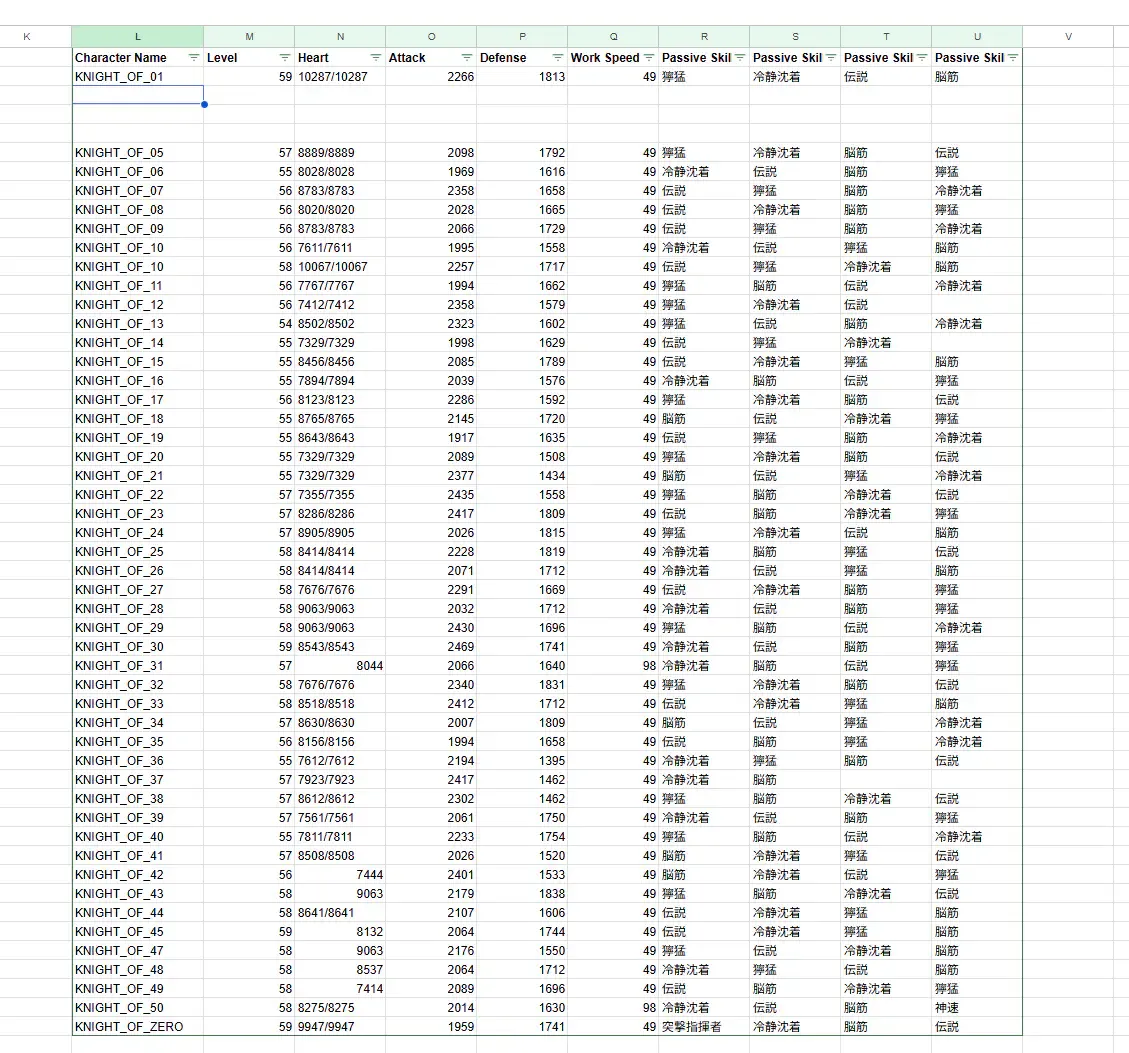
目視で抜けているのを確認して、編集した結果はこんな感じになりました。漏れている部分はありましたが、かなり手作業の量は減らせたので、とても有用なツールを作ることは出来た気がします。
このようなパルワールドのパルのステータス画面のスクショから・・・。
以下のようなリレーション形式でステータスをまとめることが出来ました。
| Character Name | Level | Heart | Attack | Defense | Work Speed | Passive Skill 1 | Passive Skill 2 | Passive Skill 3 | Passive Skill 4 |
|---|---|---|---|---|---|---|---|---|---|
| KNIGHT_OF_01 | 59 | 10287 | 2266 | 1813 | 49 | 獰猛 | 冷静沈着 | 伝説 | 脳筋 |
| KNIGHT_OF_02 | 55 | 8643 | 2323 | 1616 | 49 | 伝説 | 冷静沈着 | 脳筋 | 獰猛 |
| KNIGHT_OF_03 | 55 | 8627 | 1969 | 1742 | 49 | 獰猛 | 伝説 | 脳筋 | 冷静沈着 |
| KNIGHT_OF_04 | 57 | 8923 | 2075 | 1581 | 49 | 伝説 | 冷静沈着 | 獰猛 | 脳筋 |
| KNIGHT_OF_05 | 57 | 8889 | 2098 | 1792 | 49 | 獰猛 | 冷静沈着 | 脳筋 | 伝説 |
| KNIGHT_OF_06 | 55 | 8028 | 1969 | 1616 | 49 | 冷静沈着 | 伝説 | 脳筋 | 獰猛 |
| KNIGHT_OF_07 | 56 | 8783 | 2358 | 1658 | 49 | 伝説 | 獰猛 | 脳筋 | 冷静沈着 |
| KNIGHT_OF_08 | 56 | 8020 | 2028 | 1665 | 49 | 伝説 | 冷静沈着 | 脳筋 | 獰猛 |
| KNIGHT_OF_09 | 56 | 8783 | 2066 | 1729 | 49 | 伝説 | 獰猛 | 脳筋 | 冷静沈着 |
| KNIGHT_OF_10 | 56 | 7611 | 1995 | 1558 | 49 | 冷静沈着 | 伝説 | 獰猛 | 脳筋 |
| KNIGHT_OF_10 | 58 | 10067 | 2257 | 1717 | 49 | 伝説 | 獰猛 | 冷静沈着 | 脳筋 |
| KNIGHT_OF_11 | 56 | 7767 | 1994 | 1662 | 49 | 獰猛 | 脳筋 | 伝説 | 冷静沈着 |
| KNIGHT_OF_12 | 56 | 7412 | 2358 | 1579 | 49 | 獰猛 | 冷静沈着 | 脳筋 | 伝説 |
| KNIGHT_OF_13 | 54 | 8502 | 2323 | 1602 | 49 | 獰猛 | 伝説 | 脳筋 | 冷静沈着 |
| KNIGHT_OF_14 | 55 | 7329 | 1998 | 1629 | 49 | 伝説 | 獰猛 | 脳筋 | 冷静沈着 |
| KNIGHT_OF_15 | 55 | 8456 | 2085 | 1789 | 49 | 伝説 | 冷静沈着 | 獰猛 | 脳筋 |
| KNIGHT_OF_16 | 55 | 7894 | 2039 | 1576 | 49 | 冷静沈着 | 脳筋 | 伝説 | 獰猛 |
| KNIGHT_OF_17 | 56 | 8123 | 2286 | 1592 | 49 | 獰猛 | 冷静沈着 | 脳筋 | 伝説 |
| KNIGHT_OF_18 | 55 | 8765 | 2145 | 1720 | 49 | 脳筋 | 伝説 | 冷静沈着 | 獰猛 |
| KNIGHT_OF_19 | 55 | 8643 | 1917 | 1635 | 49 | 伝説 | 獰猛 | 脳筋 | 冷静沈着 |
| KNIGHT_OF_20 | 55 | 7329 | 2089 | 1508 | 49 | 獰猛 | 冷静沈着 | 脳筋 | 伝説 |
| KNIGHT_OF_21 | 55 | 7329 | 2377 | 1434 | 49 | 脳筋 | 伝説 | 獰猛 | 冷静沈着 |
| KNIGHT_OF_22 | 57 | 7355 | 2435 | 1558 | 49 | 獰猛 | 脳筋 | 冷静沈着 | 伝説 |
| KNIGHT_OF_23 | 57 | 8286 | 2417 | 1809 | 49 | 伝説 | 脳筋 | 冷静沈着 | 獰猛 |
| KNIGHT_OF_24 | 57 | 8905 | 2026 | 1815 | 49 | 獰猛 | 冷静沈着 | 伝説 | 脳筋 |
| KNIGHT_OF_25 | 58 | 8414 | 2228 | 1819 | 49 | 冷静沈着 | 脳筋 | 獰猛 | 伝説 |
| KNIGHT_OF_26 | 58 | 8414 | 2071 | 1712 | 49 | 冷静沈着 | 伝説 | 獰猛 | 脳筋 |
| KNIGHT_OF_27 | 58 | 7676 | 2291 | 1669 | 49 | 伝説 | 冷静沈着 | 脳筋 | 獰猛 |
| KNIGHT_OF_28 | 58 | 9063 | 2032 | 1712 | 49 | 冷静沈着 | 伝説 | 脳筋 | 獰猛 |
| KNIGHT_OF_29 | 58 | 9063 | 2430 | 1696 | 49 | 獰猛 | 脳筋 | 伝説 | 冷静沈着 |
| KNIGHT_OF_30 | 59 | 8543 | 2469 | 1741 | 49 | 冷静沈着 | 伝説 | 脳筋 | 獰猛 |
| KNIGHT_OF_31 | 57 | 8044 | 2066 | 1640 | 98 | 冷静沈着 | 脳筋 | 伝説 | 獰猛 |
| KNIGHT_OF_32 | 58 | 7676 | 2340 | 1831 | 49 | 獰猛 | 冷静沈着 | 脳筋 | 伝説 |
| KNIGHT_OF_33 | 58 | 8518 | 2412 | 1712 | 49 | 伝説 | 冷静沈着 | 獰猛 | 脳筋 |
| KNIGHT_OF_34 | 57 | 8630 | 2007 | 1809 | 49 | 脳筋 | 伝説 | 獰猛 | 冷静沈着 |
| KNIGHT_OF_35 | 56 | 8156 | 1994 | 1658 | 49 | 伝説 | 脳筋 | 獰猛 | 冷静沈着 |
| KNIGHT_OF_36 | 55 | 7612 | 2194 | 1395 | 49 | 冷静沈着 | 獰猛 | 脳筋 | 伝説 |
| KNIGHT_OF_37 | 57 | 7923 | 2417 | 1462 | 49 | 冷静沈着 | 伝説 | 脳筋 | 獰猛 |
| KNIGHT_OF_38 | 57 | 8612 | 2302 | 1462 | 49 | 獰猛 | 脳筋 | 冷静沈着 | 伝説 |
| KNIGHT_OF_39 | 57 | 7561 | 2061 | 1750 | 49 | 冷静沈着 | 伝説 | 脳筋 | 獰猛 |
| KNIGHT_OF_40 | 55 | 7811 | 2233 | 1754 | 49 | 獰猛 | 脳筋 | 伝説 | 冷静沈着 |
| KNIGHT_OF_41 | 57 | 8508 | 2026 | 1520 | 49 | 脳筋 | 冷静沈着 | 獰猛 | 伝説 |
| KNIGHT_OF_42 | 56 | 7444 | 2401 | 1533 | 49 | 脳筋 | 冷静沈着 | 伝説 | 獰猛 |
| KNIGHT_OF_43 | 58 | 9063 | 2179 | 1838 | 49 | 獰猛 | 脳筋 | 冷静沈着 | 伝説 |
| KNIGHT_OF_44 | 58 | 8641 | 2107 | 1606 | 49 | 伝説 | 冷静沈着 | 獰猛 | 脳筋 |
| KNIGHT_OF_45 | 59 | 8132 | 2064 | 1744 | 49 | 伝説 | 冷静沈着 | 獰猛 | 脳筋 |
| KNIGHT_OF_47 | 58 | 9063 | 2176 | 1550 | 49 | 獰猛 | 伝説 | 冷静沈着 | 脳筋 |
| KNIGHT_OF_48 | 58 | 8537 | 2064 | 1712 | 49 | 冷静沈着 | 獰猛 | 伝説 | 脳筋 |
| KNIGHT_OF_49 | 58 | 7414 | 2089 | 1696 | 49 | 伝説 | 脳筋 | 冷静沈着 | 獰猛 |
| KNIGHT_OF_50 | 58 | 8275 | 2014 | 1630 | 98 | 冷静沈着 | 伝説 | 脳筋 | 神速 |
| KNIGHT_OF_ZERO | 59 | 9947 | 1959 | 1741 | 49 | 突撃指揮者 | 冷静沈着 | 脳筋 | 伝説 |
| KNIGHT_OF_-1 | 50 | 4965 | 984 | 932 | 98 | 堅城の軍師 | 突撃指揮者 | 冷静沈着 | 伝説 |
今回実装したOCR処理の最終形
最終的に実装した OCR 処理の Python コードは以下のような感じです。
from google import genaifrom google.genai import typesimport base64from time import sleepfrom google.colab import userdata
def image_file_to_base64(file_path): with open(file_path, "rb") as image_file: data = base64.b64encode(image_file.read())
return data.decode('utf-8')
def generate_chunks(img_path: str): PROJECT_ID = userdata.get('gcloud_project_id') # like env in Google Colab LOCATION = userdata.get('gcloud_location') # like env in Google Colab client = genai.Client( vertexai=True, project=PROJECT_ID, location=LOCATION )
b64_image =image_file_to_base64(img_path) image1 = types.Part.from_bytes( data=base64.b64decode(b64_image), mime_type="image/webp", ) textsi_1 = """以下のカラムを持ったテーブル形式で出力して。---Character NameLevelHeartAttackDefenseWork SpeedPassive Skill 1Passive Skill 2Passive Skill 3Passive Skill 4""" prompt = """この画像からキャラクターのステータスを読み取って、Markdownのテーブル形式にして。補足や説明は不要です。"""
# model = "gemini-2.0-flash-exp" model = "gemini-1.5-pro-002" contents = [ types.Content( role="user", parts=[ image1, types.Part.from_text(prompt) ] ) ] generate_content_config = types.GenerateContentConfig( temperature = 1, top_p = 0.95, max_output_tokens = 8192, response_modalities = ["TEXT"], safety_settings = [types.SafetySetting( category="HARM_CATEGORY_HATE_SPEECH", threshold="OFF" ),types.SafetySetting( category="HARM_CATEGORY_DANGEROUS_CONTENT", threshold="OFF" ),types.SafetySetting( category="HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold="OFF" ),types.SafetySetting( category="HARM_CATEGORY_HARASSMENT", threshold="OFF" )], system_instruction=[types.Part.from_text(textsi_1)], )
chunks = [] for chunk in client.models.generate_content_stream( model = model, contents = contents, config = generate_content_config, ): chunks.append(chunk) print(chunk, end="")
return chunks
images = [ "/content/drive/MyDrive/tmp/Screenshot_20250107-045338.webp", "/content/drive/MyDrive/tmp/Screenshot_20250107-045349.webp", "/content/drive/MyDrive/tmp/Screenshot_20250107-045351.webp",
...
"/content/drive/MyDrive/tmp/Screenshot_20250107-050253.webp", "/content/drive/MyDrive/tmp/Screenshot_20250107-050254.webp"]parts = []md_tables = []for img_file_path in images: chunks = generate_chunks(img_file_path) print(chunks) for i in range(len(chunks)): print(chunks[i].candidates[0].content.parts[0].text) parts.append(chunks[i].candidates[0].content.parts[0].text) md_tables.append("".join(parts)) sleep(10) <- wait a momentprint("--------------------------------------\n")print(md_tables)まとめ
今回は、 Vertex AI の Gemini API と Google Colabolatory を使用して、パルワールドのパルのステータス画面のスクショを OCR して、テーブル形式もといリレーション形式にまとめる試みでした。
以下が本記事のまとめです。
- Vertex AI を Python から実行するためには、 OAuth2 認証が必要である。
- Google Colabolatory から Google ドライブ内のファイルを参照することが可能である。
gemini-2.0-flash-expにリクエストを頻繁に送ると、 API 利用制限に抵触して処理が止まってしまう。 10 秒ぐらい空けても止まってしまった。gemini-1.5-flash-002だと、まだ OCR 処理の能力が弱い。gemini-1.5-pro-002であれば、プロンプトによっては問題なく OCR 可能である。- その結果を ChatGPT-4o にまとめさせることは可能だが、データの一部が抜けることはある。
Google Colabolatory がかなり優秀なので、クライアントとしてはかなりこれだけで事足りそうな感じがしました。他のゲームのスクショでも可能なのかどうかも調べてみたいですね。
おしまい
以上になります!
記事を共有
この記事が役に立ったなら、ぜひ他の人と共有してください!
音楽
再生中なし