











【Python、Golang】NotionのページのプロパティをCloud SQLのPostgreSQLに記録する(第1回)

はじまり


Notionの情報をPostgreSQLに格納するツール。
僕は毎日Notionを使っています。そのNotionに入っているデータを使って日々の生活を楽にするツールを作るためにGoogle Apps Script(以下、GAS)を使っているわけなんですけど、このGASって実行時間の上限が短いんですよね。手動実行だと最大6分、時間主導実行だと最大30分の上限が設けられています。(時間主導実行の上限については、公にGoogleから掲示されているわけではないんですけど、2024-11-25時点では確かにその間だけ実行できるんですよね。)


しかし、Notionのページを取得する処理を行う際に、ページの数が1700個ぐらいになってくると、その最大30分上限ですらオーバーするようになってきます。なぜなら、Notion APIの「Query a database」エンドポイントでは、リクエスト1回につき100件までのページしか取得できず、リクエストの回数が多くなるためです。
じゃあ、APIを非同期処理の中で叩けばいいじゃないかと言うと、それではダメなんです。Notion APIで101件目から先のページを取得するためには100件目までを取得したレスポンス内にある「next_cursor」を含めてリクエストしなければならないからです。
じゃあ、「next_cursor」をGASのScriptPropertyとかの中に入れて、再度同じGASを実行すればいいとも思いましたが、以前にトリガーの生成をコード内で行った時に上手く動かなかったんですよね・・・。だから、これはちょっとGASで作るのには限界を感じました。
そこで、今回はNotionのページを取得したら、そのページの情報をPostgreSQLデータベースに格納するツールを、Cloud Functionsで作っていきたいと思います。Cloud Functionの実行時間の上限は、2024-11-25時点で、第2世代としてデプロイすれば最大60分です。そして、その関数でDBにデータを入れてしまえば、GASからの1度のリクエストで全てのレコードを参照することが出来るようになります。
今回のツールのイメージはこんな感じです。Cloud Functionsが2種類必要になってきますかね。
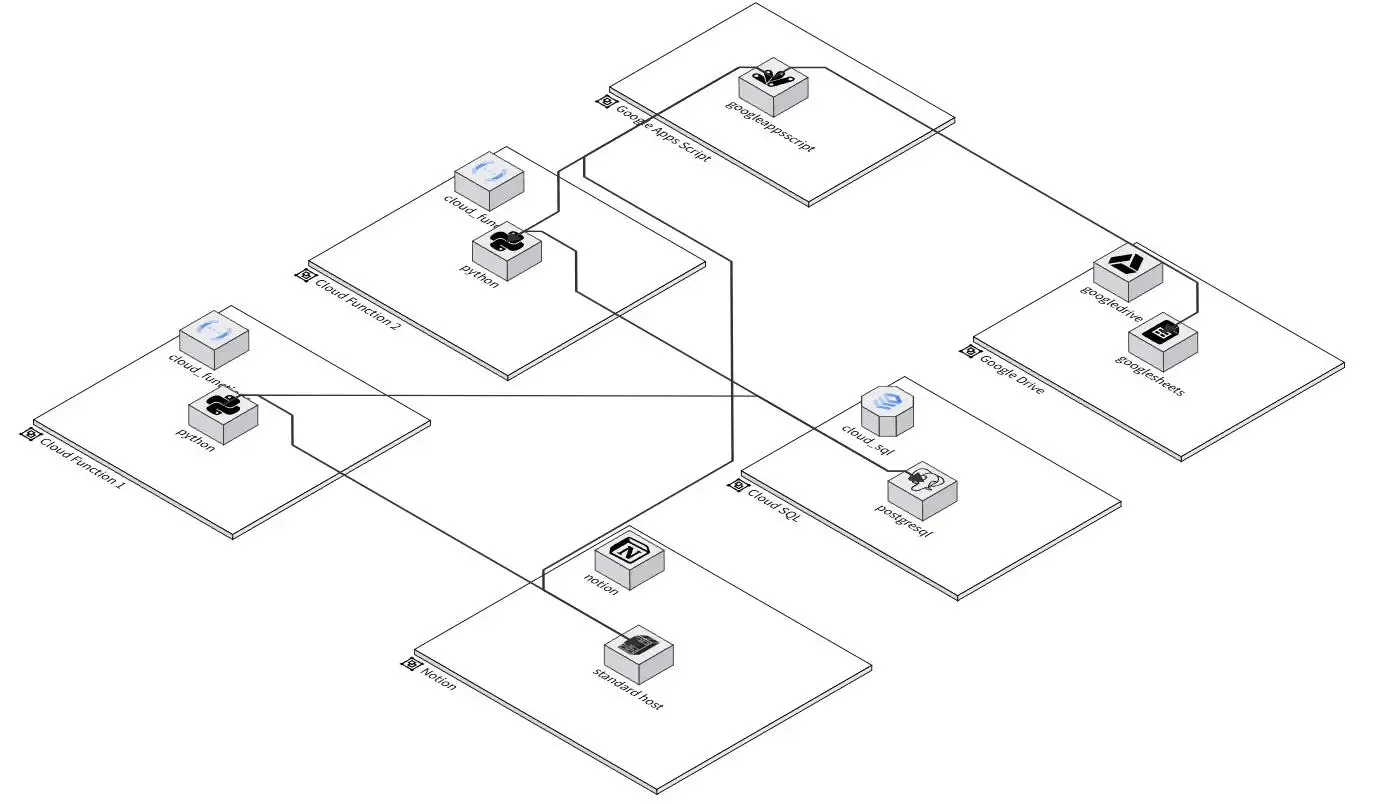
Goは今回相性が悪かった。
ところで、当初はこのツールをGoで作ろうとしたんですけど、今回の目的を果たすためには少し相性が悪かったです。(Goの方がPythonよりも遥かに速いし、メモリ使用量も少ないので。) 以下に、悪かった点を書きます。
Notion APIと相性が悪い。
Notion APIから取得できるJSONをGoで取得して構造体に反映させるのって、けっこう面倒くさいんですよね。煩雑です。そのために、「go-notion」というライブラリを使ったんですけど、「ID」カテゴリのプロパティを取得することが出来ない。(これは自分で直せばいい気もしますが・・・。)
しかしさらに、この「go-notion」ライブラリの更新が鈍重なんですよね。メインリポジトリの更新日が、2023-03-01と・・・、あまり活発なリポジトリではないことが窺えます。(2024-11-25に確認しました。)
まあでも、大きなリポジトリの運営って絶対大変でしょうからね・・・。そこはしょうがない・・・。
SQLと相性が悪い。
GoでPostgreSQLを叩いていこうと思いました。しかし、DBのカラムが増えたり名前を変えたりして、DBへのクエリを変えると同時に構造体も編集するのはいちいち面倒くさいですね。なので、今回は「GORM」ライブラリでDBのテーブルと構造体のObject-Relation-Mappinngをしていきたいと思います。
しかし、今回はこれが上手くいきませんでした。
まず厄介なことに、GoのSQLドライバーは、DBのカラムの中に配列を入れることが出来ないらしいです。
GORMライブラリでやろうとすると、DBに配列を持てません。なので、例えばカラムをテキスト型にしてCSVを入れようとすると、SELECT文でテキスト型のカラムを参照する時に構造体の配列に変換できずにエラーが発生します。つまり、構造体に配列の属性を持てない。
こうなってしまうと、DBを参照して配列に変換するための構造体まで準備しなくてはなりません。元々、リレーションと構造体の両方を治すのが面倒だからORMを使用したいというのに、これでは本末転倒です。全然開発が進まない・・・。
unsupported type []string, a slice of string
PythonでPostgreSQLに格納する。
Goで今回のような処理を実装しようとすると、どうにも開発が鈍足になり、成果物も完璧なものにはならないことが分かりました・・・。
なので、今回のNotionのページをPostgreSQLに記録するツールは、Pythonで実装していこうと思います。
SQLAlchemyを使う。
今回、Cloud SQLを使っていくので、公式のチュートリアルを確認すると、SQLAlchemyを使っていました。
なので、Cloud SQLにDBを作る前に、ローカルでSQLAlchemyを使ってPostgreSQLに記録する処理を作りたいと思います。
SQLAlchemyでInsert文を作る。
SQLAlchemyでPostgreSQLのDBにデータを格納していきます。
今回は例として、Create文とInsert文だけ。
from sqlalchemy import create_engine, text
# PostgreSQL接続情報DATABASE_URL = "postgresql+psycopg2://username:password@localhost:5432/dbname"
# SQLAlchemyエンジンのセットアップengine = create_engine(DATABASE_URL)
# テーブル作成クエリcreate_table_query = """CREATE TABLE IF NOT EXISTS records ( id SERIAL PRIMARY KEY, name VARCHAR(255) NOT NULL, number INTEGER NOT NULL, is_active BOOLEAN NOT NULL, account_number INTEGER NOT NULL, is_verified BOOLEAN NOT NULL, score VARCHAR(50) NOT NULL, url TEXT, extra_info TEXT);"""
# データ挿入クエリinsert_query = """INSERT INTO records (name, number, is_active, account_number, is_verified, score, url, extra_info)VALUES (:name, :number, :is_active, :account_number, :is_verified, :score, :url, :extra_info);"""
# データ(複数レコード)record = ["tanaka", 10, True, 67890, False, "5", "https://www.google.co.jp/", None]
# 実行with engine.connect() as connection: # テーブル作成 connection.execute(text(create_table_query)) print("Table created or already exists.")
# データを挿入 connection.execute(text(insert_query), record)
print("Multiple records inserted successfully!")SQLAlchemyで一気にInsertできるクエリを作る。
SQLAlchemyを使う際のトピックとしては、Insert文の作り方ですね。
Insertする際に、DBに1文ずつ渡すのでは時間が掛かり過ぎです。なので、SQLAlchemyのInsert実行のメソッドは1度だけ実行するようにしたい・・・。しかし、SQLAlchemyでググった際に、SQLAlchemyのメソッド内でInsertを一気に実行している記事が見られました。
まあそれでもいいんですけど・・・、でも個人的には、Insert実行のメソッドにはクエリを渡すようにしたいんですよね・・・。DBを操作するのに、自分が書いていない関数でやるのって、なんかスキルが身に付いている感じがしない・・・。だからクエリを渡す方法でやりたい・・・。
そこでまたSQLAlchemyでググったのですが・・・、Insert文をクエリの中に1つしか書いていない情報しか見つけられませんでした。なのでここに動いたものを書いておきます。
from sqlalchemy import create_engine, text
# PostgreSQL接続情報DATABASE_URL = "postgresql+psycopg2://username:password@localhost:5432/dbname"
# SQLAlchemyエンジンのセットアップengine = create_engine(DATABASE_URL)
# テーブル作成クエリcreate_table_query = """CREATE TABLE IF NOT EXISTS records ( id SERIAL PRIMARY KEY, name VARCHAR(255) NOT NULL, number INTEGER NOT NULL, is_active BOOLEAN NOT NULL, account_number INTEGER NOT NULL, is_verified BOOLEAN NOT NULL, score VARCHAR(50) NOT NULL, url TEXT, extra_info TEXT);"""
# データ挿入クエリinsert_query = """INSERT INTO records (name, number, is_active, account_number, is_verified, score, url, extra_info)VALUES (:name, :number, :is_active, :account_number, :is_verified, :score, :url, :extra_info);"""
# データ(複数レコード)records = [ ["tanaka", 10, True, 67890, False, "5", "https://www.google.co.jp/", None], ["suzuki", 25, False, 12345, True, "8", "https://www.example.com/", "extra data"], ["yamada", 30, True, 67891, False, "3", "https://www.test.com/", None],]
# 実行with engine.connect() as connection: # テーブル作成 connection.execute(text(create_table_query)) print("Table created or already exists.")
# 複数レコードのデータを挿入 connection.execute( text(insert_query), [ { "name": record[0], "number": record[1], "is_active": record[2], "account_number": record[3], "is_verified": record[4], "score": record[5], "url": record[6], "extra_info": record[7], } for record in records ] ) print("Multiple records inserted successfully!")上記の処理はChatGPTに出してもらったんですけど、(だからもう少し頑張ってググれば記事はあるのだろうか。)
僕はこの処理をさらに関数化して、その関数にはクエリとレコードを渡すようにして、正規表現でクエリ内に書いてあるカラム名を抽出して、リスト内包表記で辞書を作成する処理にしました。
from pprint import pprintfrom typing import TypedDict, Final, Listimport reimport sqlalchemyimport inspect
def execute_db_ops(engine: sqlalchemy.engine.base.Engine, query: str, records: List[List[any]] = None): """
""" def extract_columns(query): match = re.search(r"\((.*?)\)", query.text) if match: columns = match.group(1).split(",") return [column.strip() for column in columns] # remove spaces return []
func_name = inspect.currentframe().f_code.co_name pprint(f"{func_name}: start processing into PostgreSQL...") with engine.begin() as conn: if records: pprint(f"{func_name}: processing with records into PostgreSQL...") columns = extract_columns(query) columns = [c.replace(":", "") for c in columns] pprint(f"{func_name}: columns:") pprint(columns) mapped_records = [{column: record[i] for i, column in enumerate(columns)} for record in records] pprint(f"{func_name}: mapped_records:") pprint(mapped_records) conn.execute(query, mapped_records) pprint(f"{func_name}: completed processing with records into PostgreSQL.") else: conn.execute(query) pprint(f"{func_name}: completed processing into PostgreSQL.")また、ここでもう一つ気を付けたのが、このSQLAlchemy実行用の関数の引数に辞書型の変数を渡さないようにしたことです。
今後このツールを改造して、このPythonのソースコードをコンパイル出来るようになったら、スタックメモリを使える処理が出てくるかもしれません。しかし、辞書型を渡す処理は間違いなくヒープメモリを使うことになります。そして、ヒープメモリを使う方がメモリ使用量が増えるんですよね多分。あと処理も遅くなります。
あと、今回使うCloud Functionsでは、最大メモリ使用サイズによって費用が変わるので、なるべくスタックメモリを使って余計なリソースを使わないで節約したいです。もしかしたらCloud Functions以外のサービスでデプロイする時にもコストを抑えられるかもしれません。
日本語ロケールの設定
DBに日本語の情報を使う際に、利用するサーバに日本語ロケールを設定します。こうしないとDBで日本語を使えなかったりします。
sudo apt-get install language-pack-jasudo dpkg-reconfigure localesそしたら、PostgreSQLを起動して、コンソールに入ります。
sudo /sbin/service postgresql startsudo su - postgresSQLコンソールに入る。
psql -d postgresユーザーとDBを作ります。DBのロケールを日本語に設定します。
CREATE USER myuser WITH PASSWORD 'mypassword';CREATE DATABASE testdb OWNER myuser ENCODING 'UTF8' lc_collate 'ja_JP.UTF-8' lc_ctype 'ja_JP.UTF-8' template 'template0';GRANT ALL PRIVILEGES ON DATABASE testdb TO myuser; GRANT USAGE, CREATE ON SCHEMA PUBLIC TO myuser;PostgreSQLへの格納が完了。
とりあえずはPostgreSQLへの格納が終わったので、次にこのDBをCloud SQL上に作っていきたいと思います。
Cloud SQLを使う。
それでは次に、Cloud SQL上にPostgreSQLデータベースを作成して、同様にNotionの情報を格納していきます。 作業の流れは、「Cloud SQL Auth Proxy を使用して Cloud SQL for PostgreSQL に接続する」のGoogle Cloud公式ガイドを参考にやっていきます。
Cloud SQL インスタンスを作成する
Google Cloud コンソールで、Cloud SQL の「インスタンス」 ページに移動します。
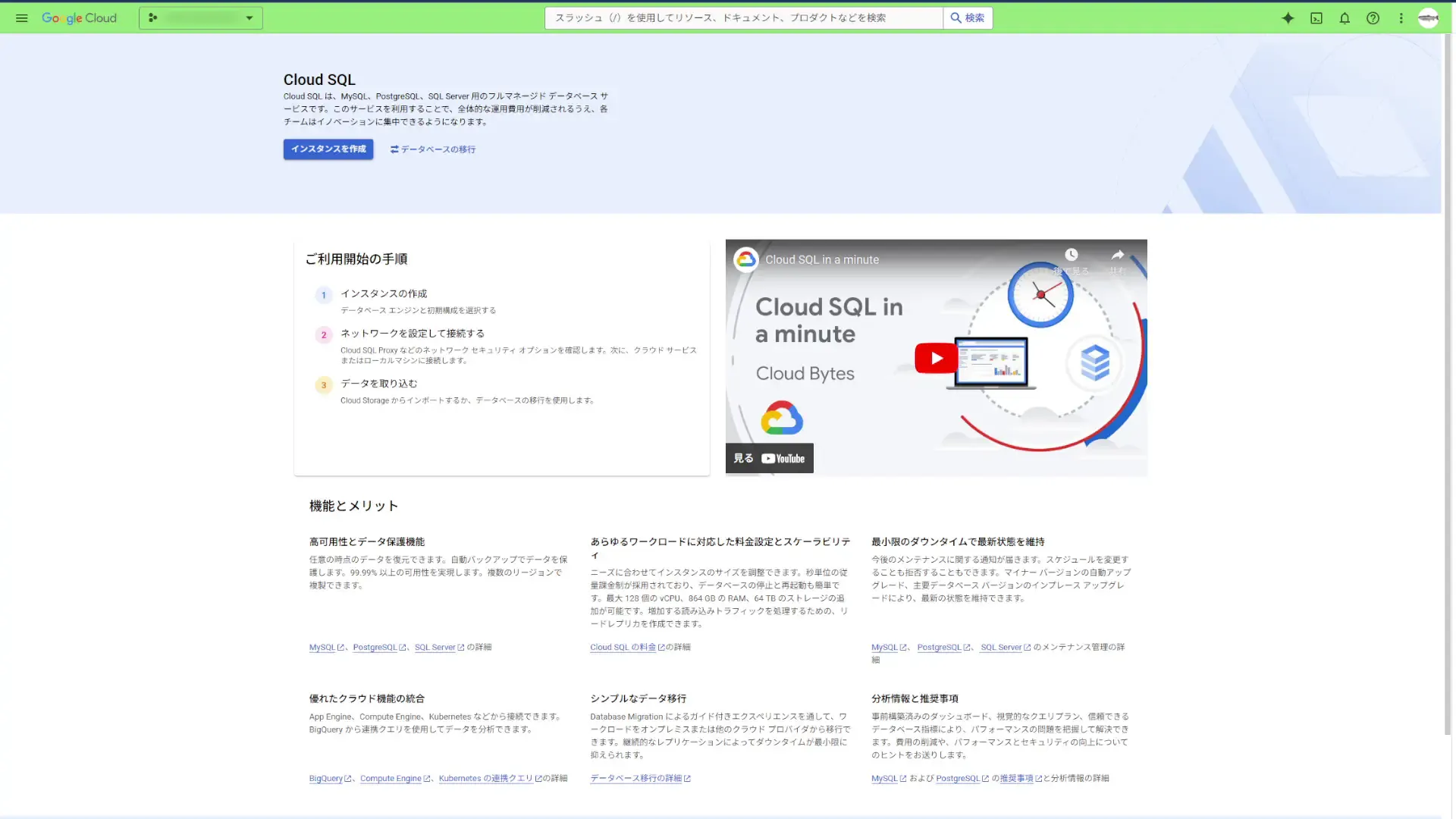
「インスタンスを作成」をクリックしてインスタンス作成画面に移動しようとすると「Compute Engine API」を有効にしておく必要があるので有効にします。有効にすると、インスタンスの作成画面が表示されます。
Cloud SQLのエディションには「Enterprise plus」と「Enterprise」の2種類あるらしく、「Enterprise」の方が安くなりそうです。今回は、「Enterprise」にしておきます。
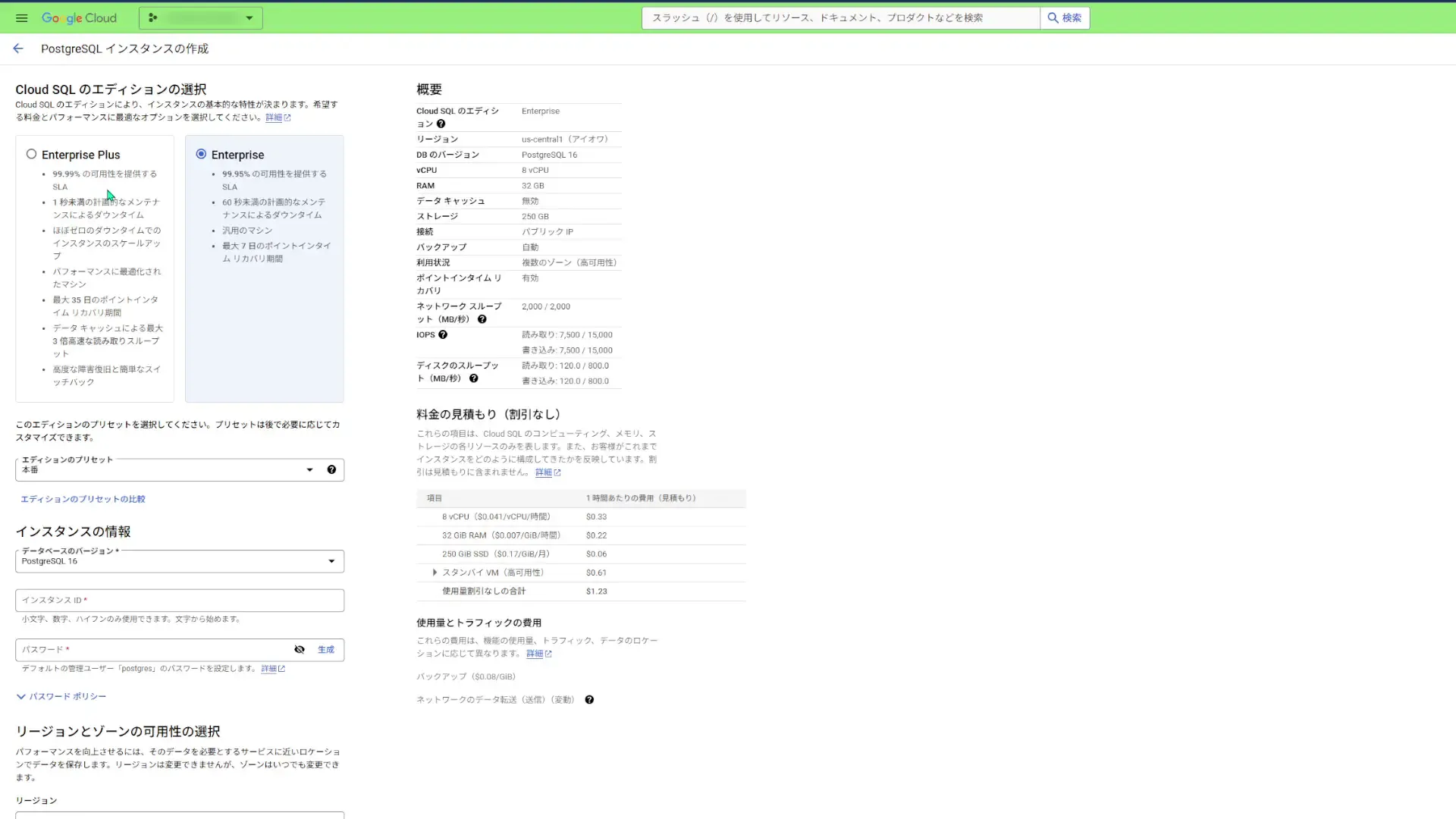
エディションのプリセットは「サンドボックス」にします。そしてインスタンスの情報は以下の通りにしておきます。
- データベースのバージョン:PostgreSQL 16
- インスタンス-ID:testdb-01
- パスワード:(任意の文字列)
あと、「リージョンとゾーンの可用性の選択」です。
「サンドボックス」エディションでは、「シングルゾーン」しか選べないようなのですが、ここではなんかゴニョゴニョ編集できましたね・・・。「複数のゾーン」にして作成すると引っかかるのか?
「マシンの構成」やら「ストレージ」やら、色々と設定できるみたいですが、今回はデフォルト設定にしておきます。
「接続」では、デフォルト設定の「パブリックIP」を選択しておきます。新しいネットワークには今回特に入力しません。
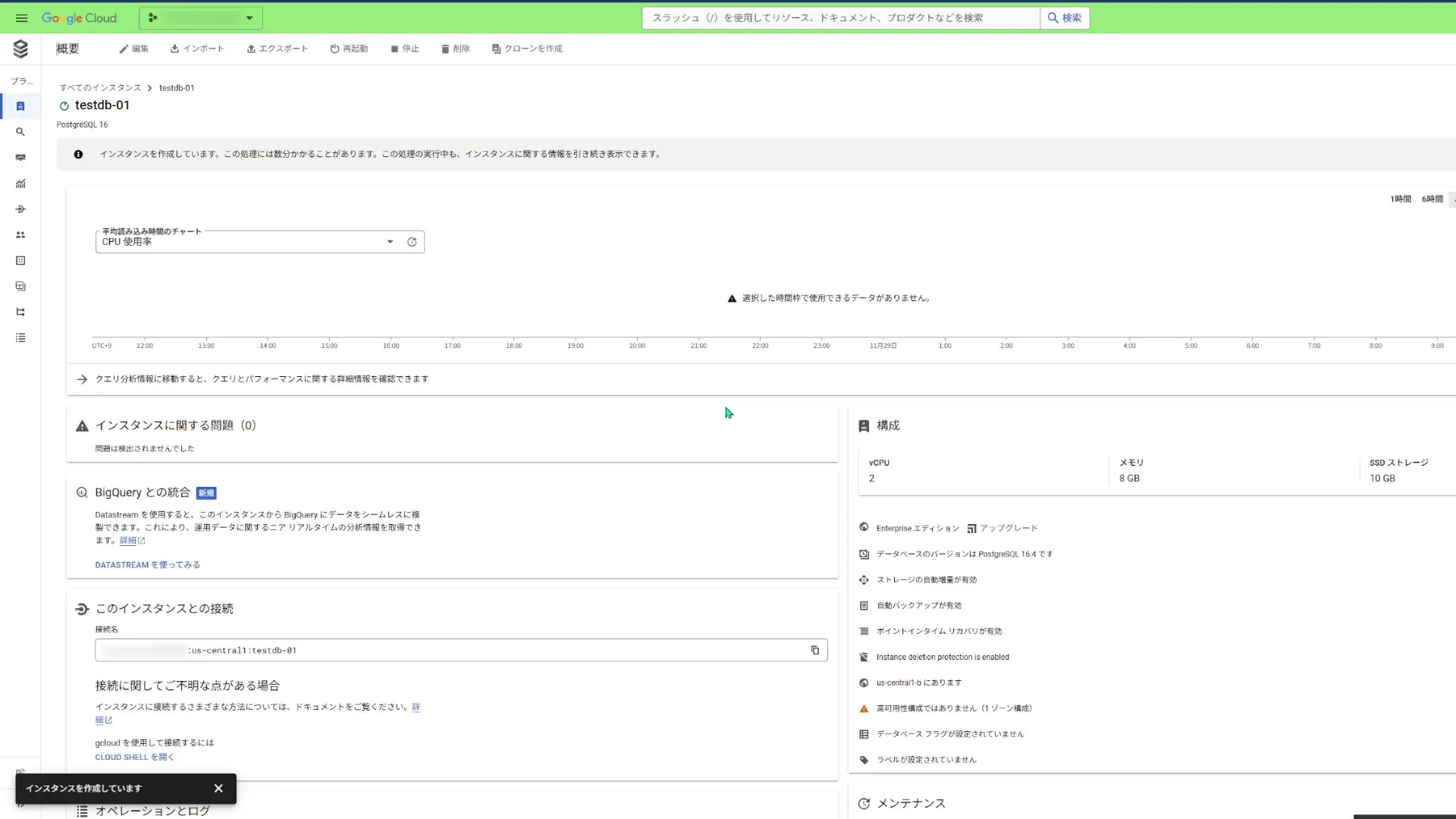
そしたら、インスタンスを作成します。作成が始まると、インスタンスの概要を閲覧できる画面が表示されます。
Cloud SQL Auth Proxy クライアントをインストールする。
インスタンスを作成したら、そのインスタンスに認証できるツール「Cloud SQL Auth Proxy」のクライアントをインストールします。
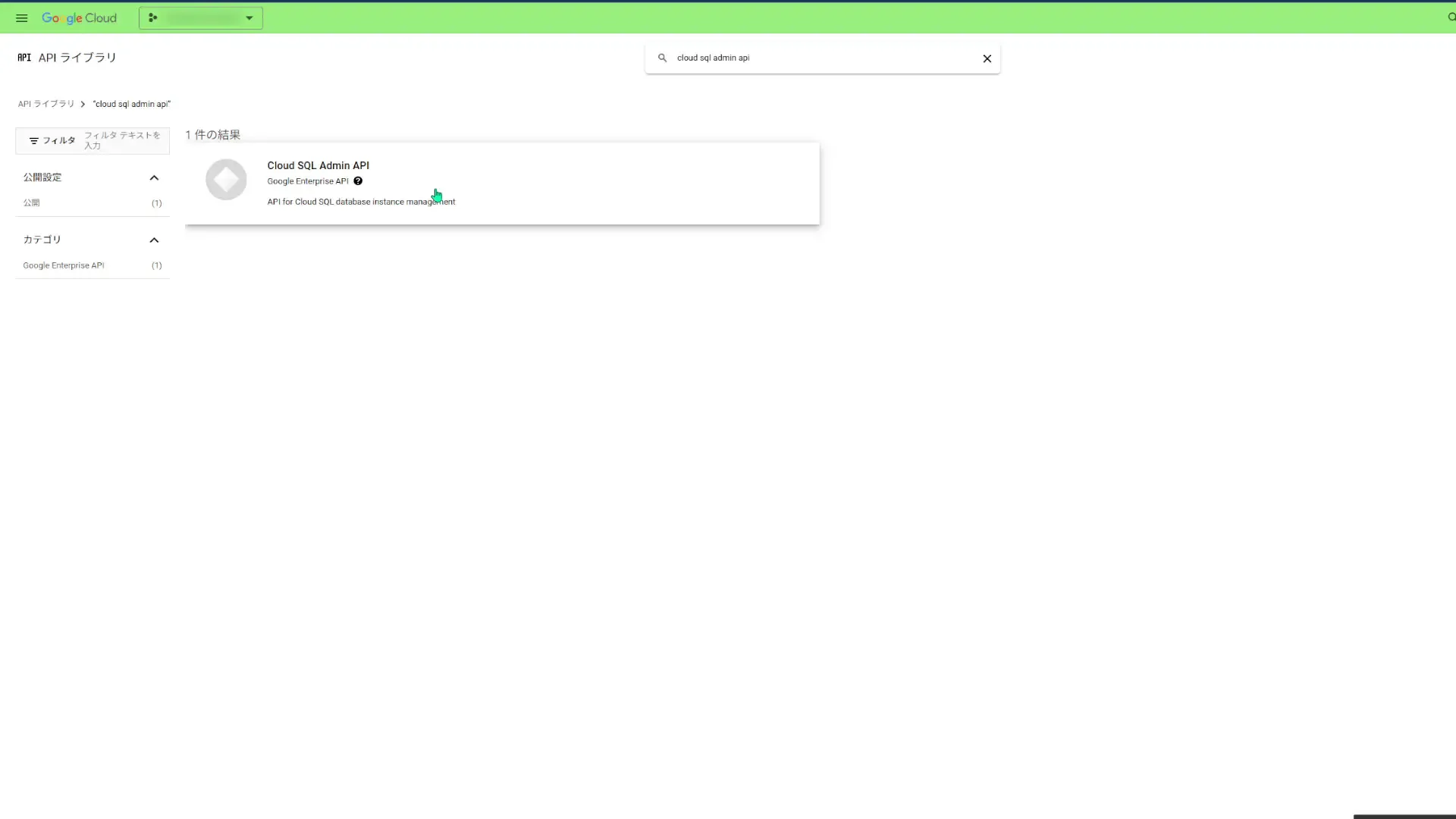
まずは、「APIとサービス」より「APIとサービスを有効にする」をクリックして、「Cloud SQL Admin API」を有効にします。
先程Pythonで開発したツールが置いてある場所に、Cloud SQL Auth Proxy クライアントを設置します。
OSがDebianもしくはUbuntuであれば、以下のコマンドでダウンロードします。
curl -o cloud-sql-proxy https://storage.googleapis.com/cloud-sql-connectors/cloud-sql-proxy/v2.13.0/cloud-sql-proxy.linux.amd64Cloud SQL Auth Proxy を実行可能にします。
chmod +x cloud-sql-proxyCloud SQL Auth Proxyで認証する。
それでは次に、Cloud SQL Auth Proxyで認証していきます。
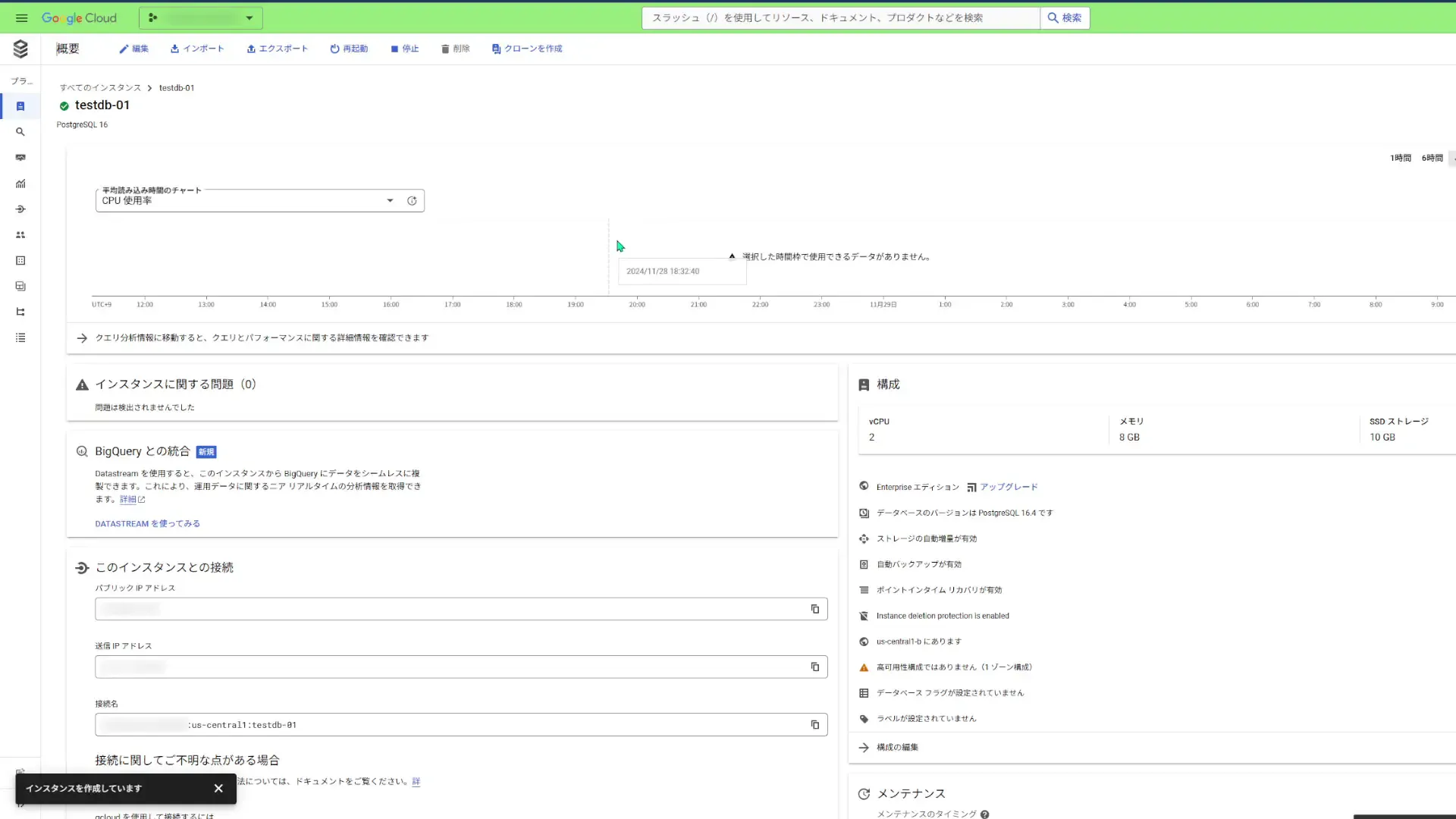
まずは、Google Cloud コンソール内でDBインスタンスの画面から、「このインスタンスと接続」セクションで「接続名」をコピーします。接続名の形式は projectID:region:instanceID です。
OSがDebianもしくはUbuntuであれば、以下のコマンドでログインします。
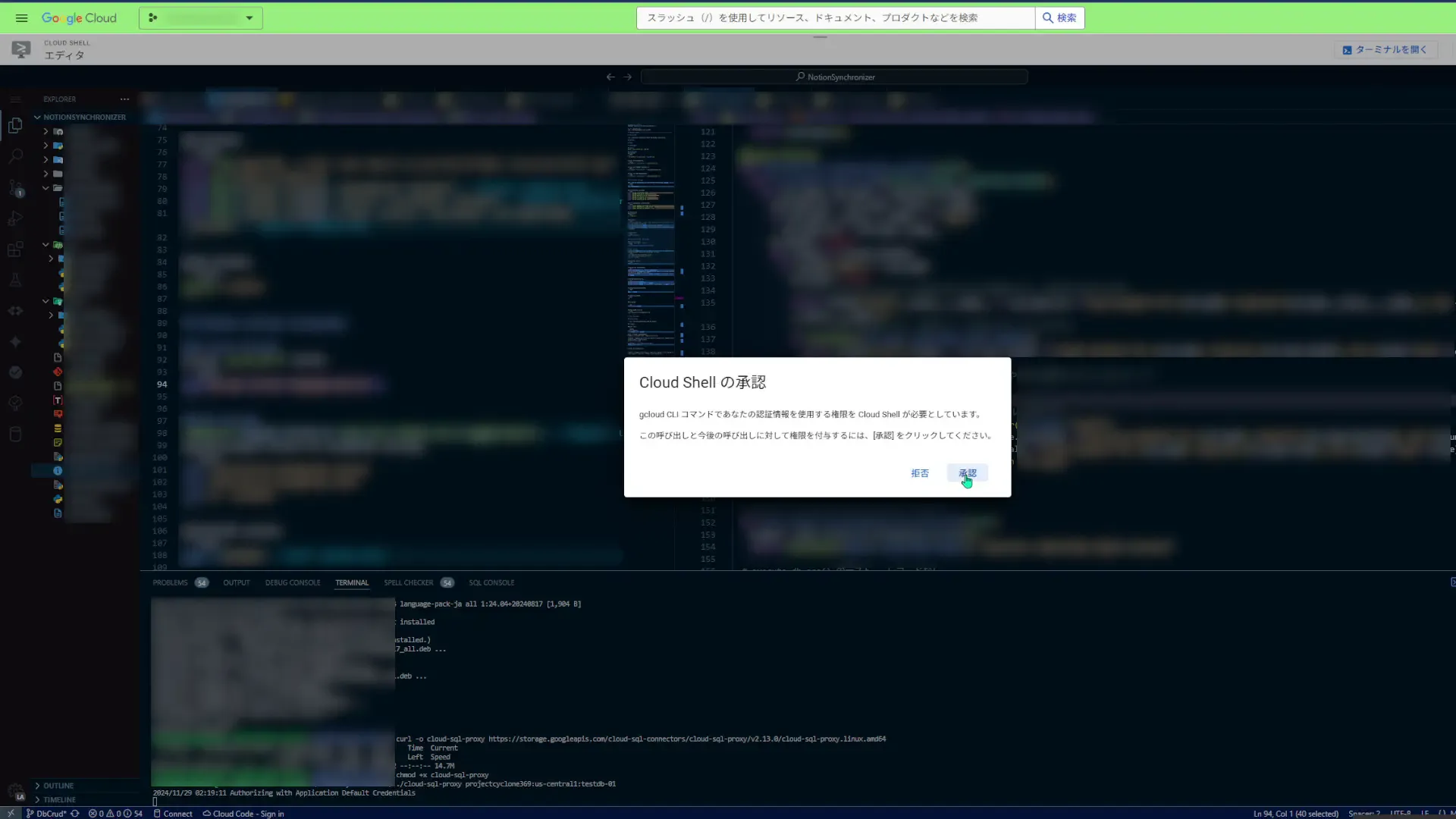
./cloud-sql-proxy projectID:region:instanceIDログインしようとすると、認証の作業が入ります。僕の場合はCloud Shell上で作業していたのでこんな感じになりました。
こんな感じのメッセージが表示されると、Cloud SQLが外部からのリクエストをListenしている状態になります。
2024/11/29 02:19:18 The proxy has started successfully and is ready for new connections!そしたら今度は、Cloud SQL上のPostgreSQLに接続します。 その接続をする際に、必ずパスワードの入力が求められるので、Cloud SQLのコンソール上でサイドバーから「ユーザー」を選択して、表示された画面内でスーパーユーザー「postgres」のパスワードを設定しておきます。
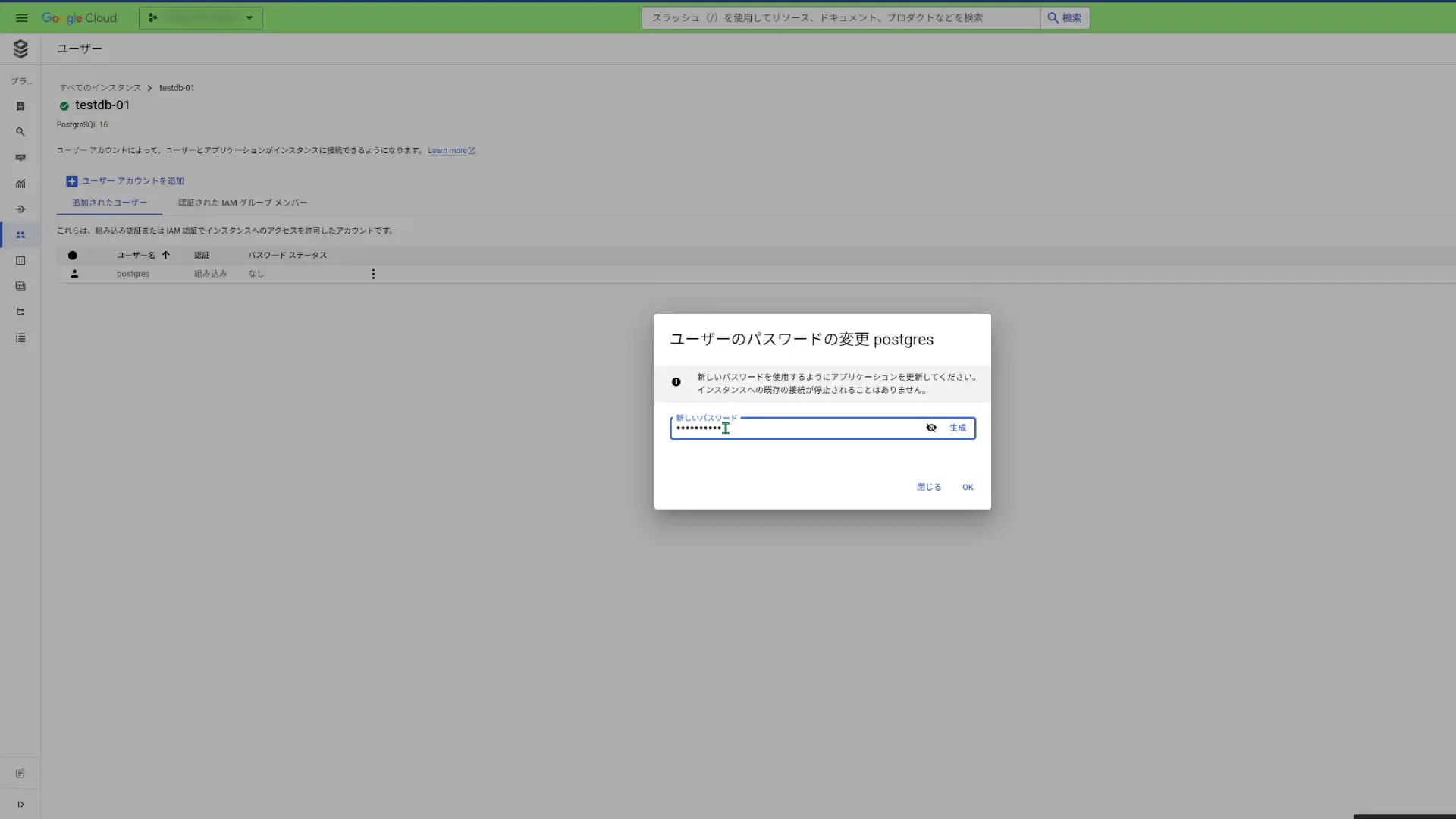
設定したら、その「postgres」で先程作ったPostgreSQLインスタンス内にデフォルトで作成される「postgres」DBにログインします。
psql "host=127.0.0.1 port=5432 sslmode=disable dbname=postgres user=postgres"ちなみに、Cloud SQLのコンソール上でサイドバーにある「データベース」をクリックすると、現在存在するデータベースを確認できます。
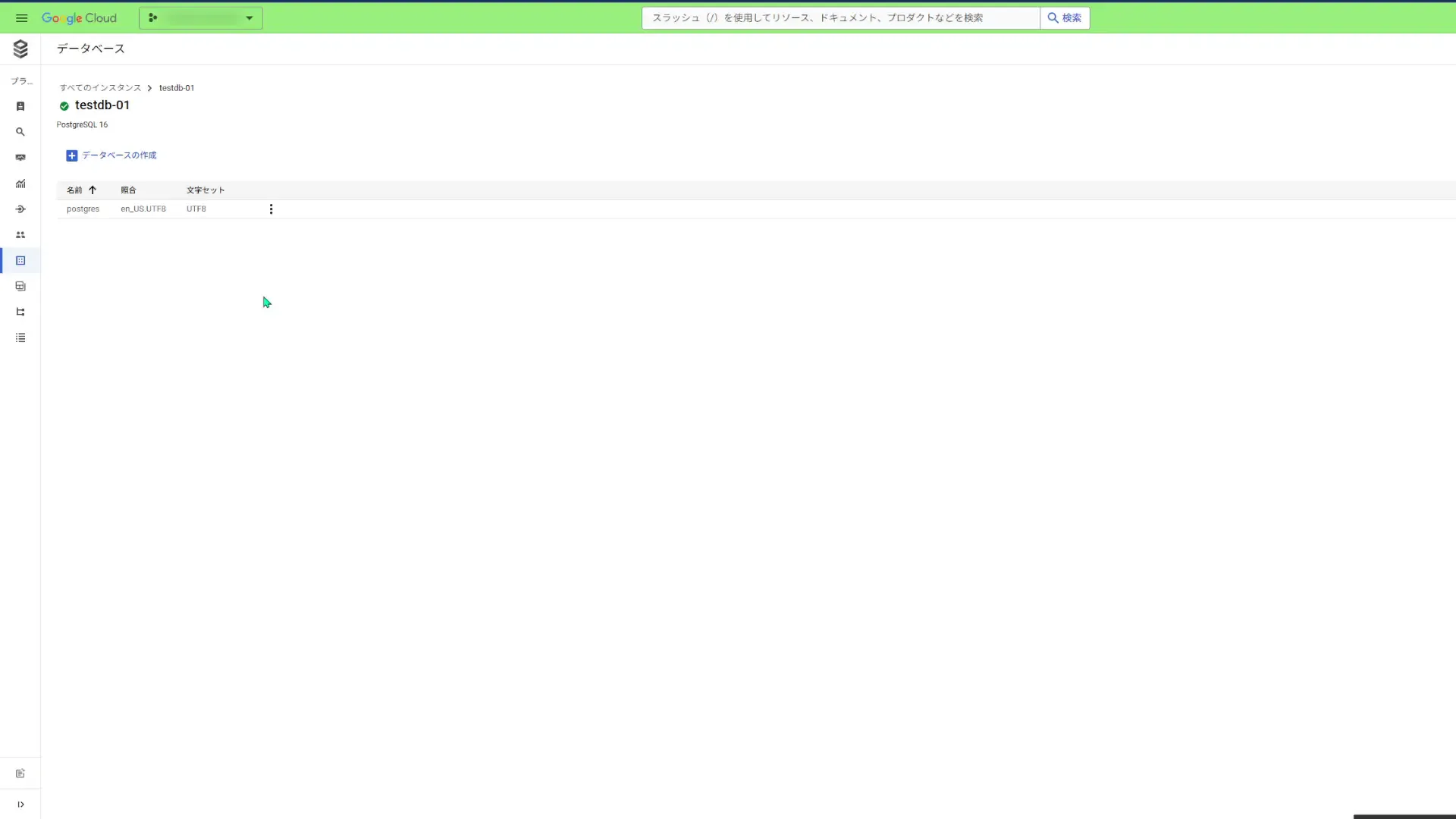
ユーザー、ロールおよびデータベースを作成する。
DBに接続できたら、まずはユーザーを作成します。
CREATE USER myuser WITH PASSWORD 'mypassword';このSQLコマンドを実行して、現在のユーザーのロールと権限を確認できます。
SELECT * FROM pg_roles WHERE rolname = 'myuser';接続中のユーザーがsuperuser相当の状態で、myuserにロールを付与します。 次のようなSQLコマンドを実行して、ロールを付与できます。
GRANT myuser TO current_user;そして、テーブルを作成します。日本語ロケールで作ります。
CREATE DATABASE lmakdb OWNER myuser ENCODING 'UTF8' lc_collate 'ja_JP.UTF-8' lc_ctype 'ja_JP.UTF-8' template 'template0';DBを使いやすくします。
GRANT ALL PRIVILEGES ON DATABASE testdb TO myuser; GRANT USAGE, CREATE ON SCHEMA PUBLIC TO myuser;これにて、データベースの作成は完了です。
先程、GRANT myuser TO current_user;を実行した理由は、実行しないでテーブルを作成しようとした時に以下のエラーが発生したためです。
ERROR: must be member of role "test"今回作成したユーザーである「myuser」でそのエラーを回避するためには、どうやら「myuser」をsuperuser相当のユーザーからロールを付与されたユーザーにする必要があるみたいです。そうしないとテーブルを作成できません。 これはPostgreSQLの仕様のようです。

そして、既存のテーブルおよび作成されたテーブルを「\l」で確認してみると、
Name | Owner | Encoding | Locale Provider | Collate | Ctype | ICU Locale | ICU Rules | Access privileges---------------+-------------------+----------+-----------------+-------------+-------------+------------+-----------+----------------------------------------- cloudsqladmin | cloudsqladmin | UTF8 | libc | en_US.UTF8 | en_US.UTF8 | | | testdb | myuser | UTF8 | libc | ja_JP.UTF-8 | ja_JP.UTF-8 | | | =Tc/myuser + | | | | | | | | myuser=CTc/myuser postgres | cloudsqlsuperuser | UTF8 | libc | en_US.UTF8 | en_US.UTF8 | | | template0 | cloudsqladmin | UTF8 | libc | en_US.UTF8 | en_US.UTF8 | | | =c/cloudsqladmin + | | | | | | | | cloudsqladmin=CTc/cloudsqladmin template1 | cloudsqlsuperuser | UTF8 | libc | en_US.UTF8 | en_US.UTF8 | | | =c/cloudsqlsuperuser + | | | | | | | | cloudsqlsuperuser=CTc/cloudsqlsuperuser(5 rows)ちなみに、先程作成したユーザーとロールは、Cloud SQLへのセッションを閉じても、Cloud SQL上のインスタンスを停止しても消えません。
また、hostをPythonでホストに設定していた部分を「localhost」からデータベースが置いてあるIPアドレスを指定すれば、これまでと同じようにテーブルの作成、レコードの追加などを行うことが出来ます。
Query InsightsでDBの状況を確認する。
テーブルを作成できたら、DBホストのアドレスを変えること以外は、先程ローカルで作成したPostgreSQLデータベースに対する処理と何も変わらないので、とりあえずNotionの情報をテーブルに格納しておきます。
そして、Cloud SQLのコンソール上でサイドバーにある「Query Insights」をクリックして、Query Insightsを有効にします。
Query Insightsを有効にすると、このようなダッシュボードが表示されました。
認証に失敗するとエラー扱いになるようなので、赤いチャートが目立っています。
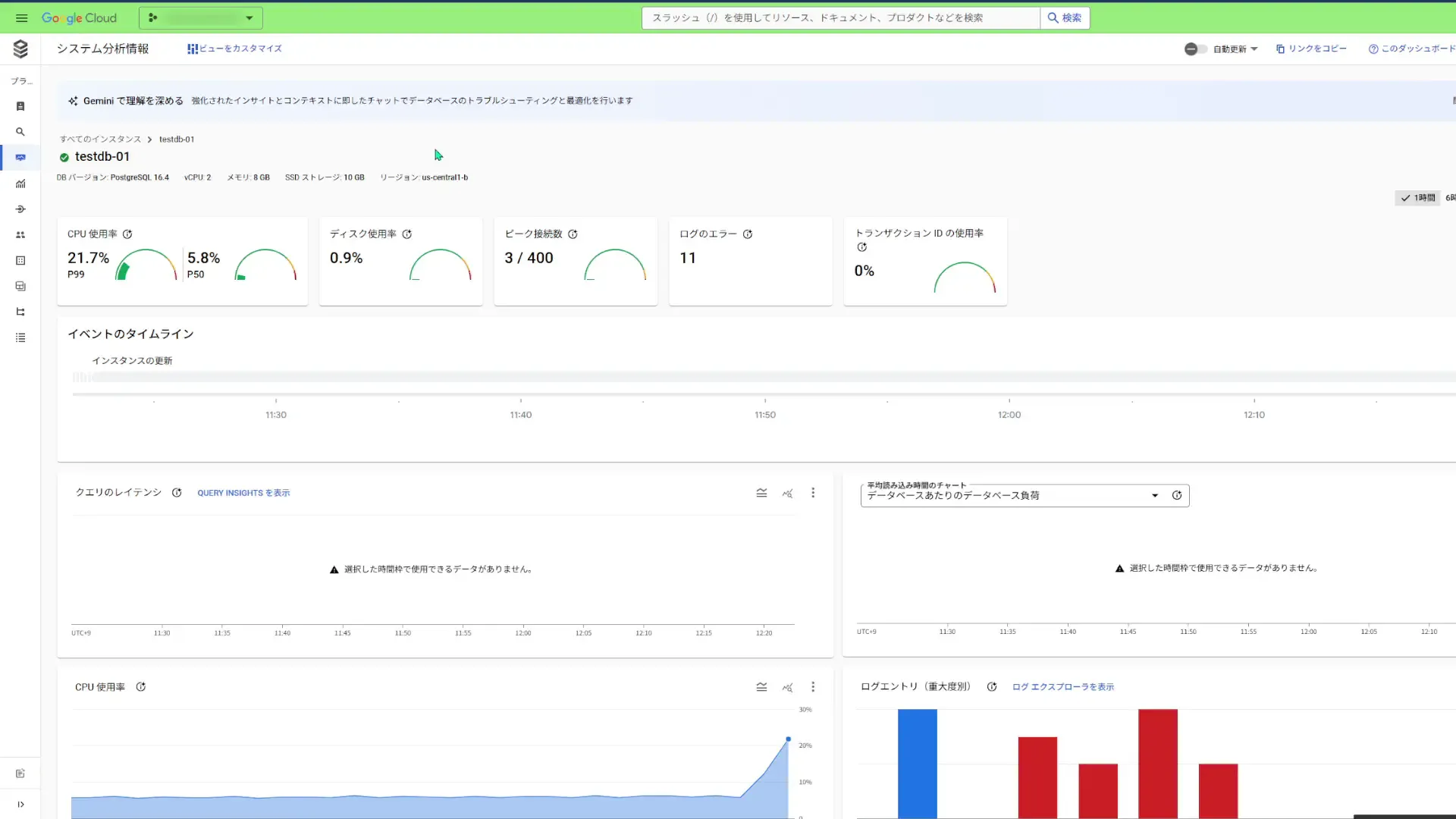
クエリのレイテンシー、CPU使用率を確認できて、ディスクストレージがあとどれぐらいで満杯になるかどうかを確認することも出来ます。
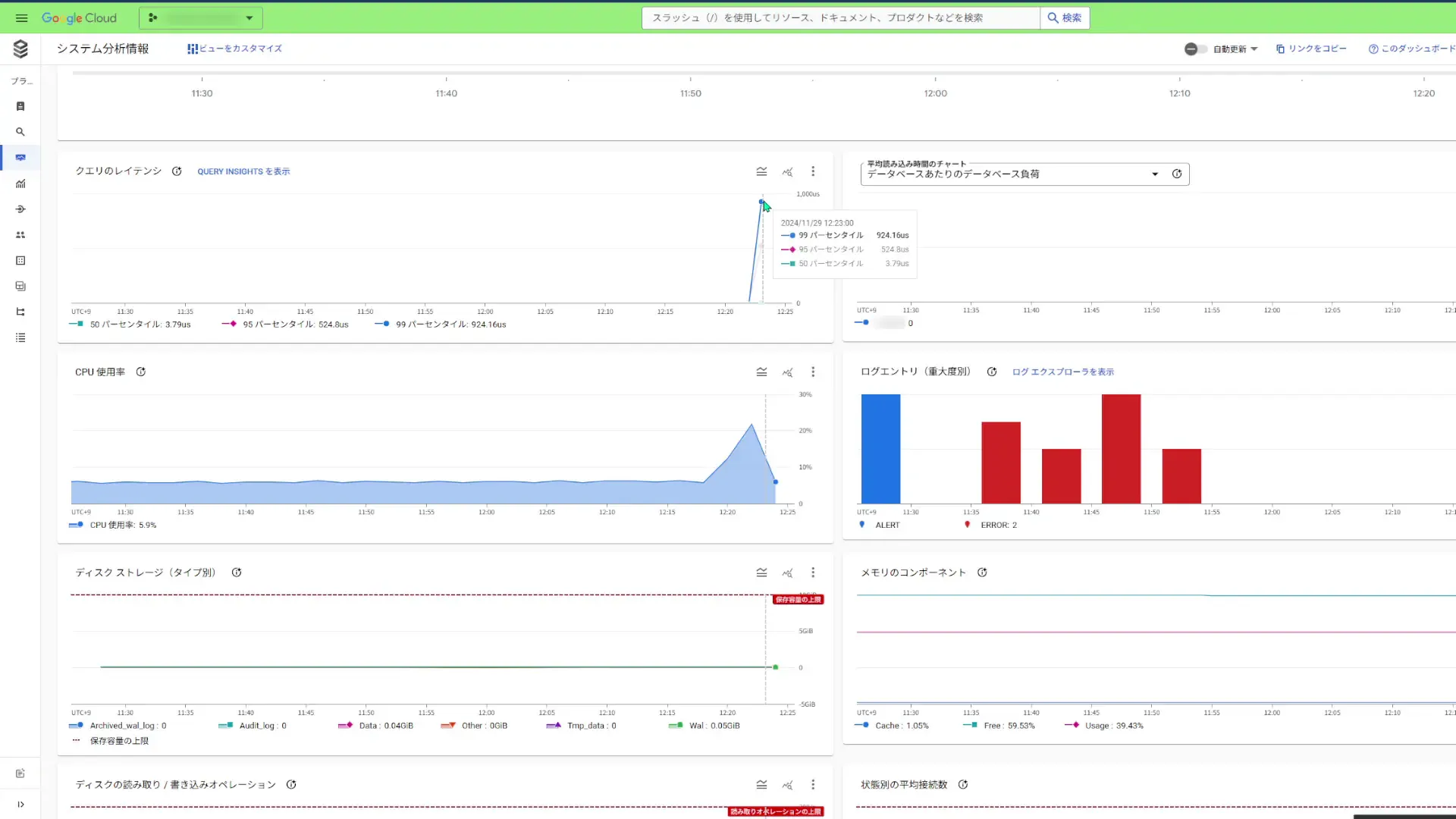
その他にも色々な指標を確認することが出来ます。個人的には、もう少し大量のデータを参照して、「オペレーション別の処理行数」がどのように推移していくのかを把握しておきたいですね。
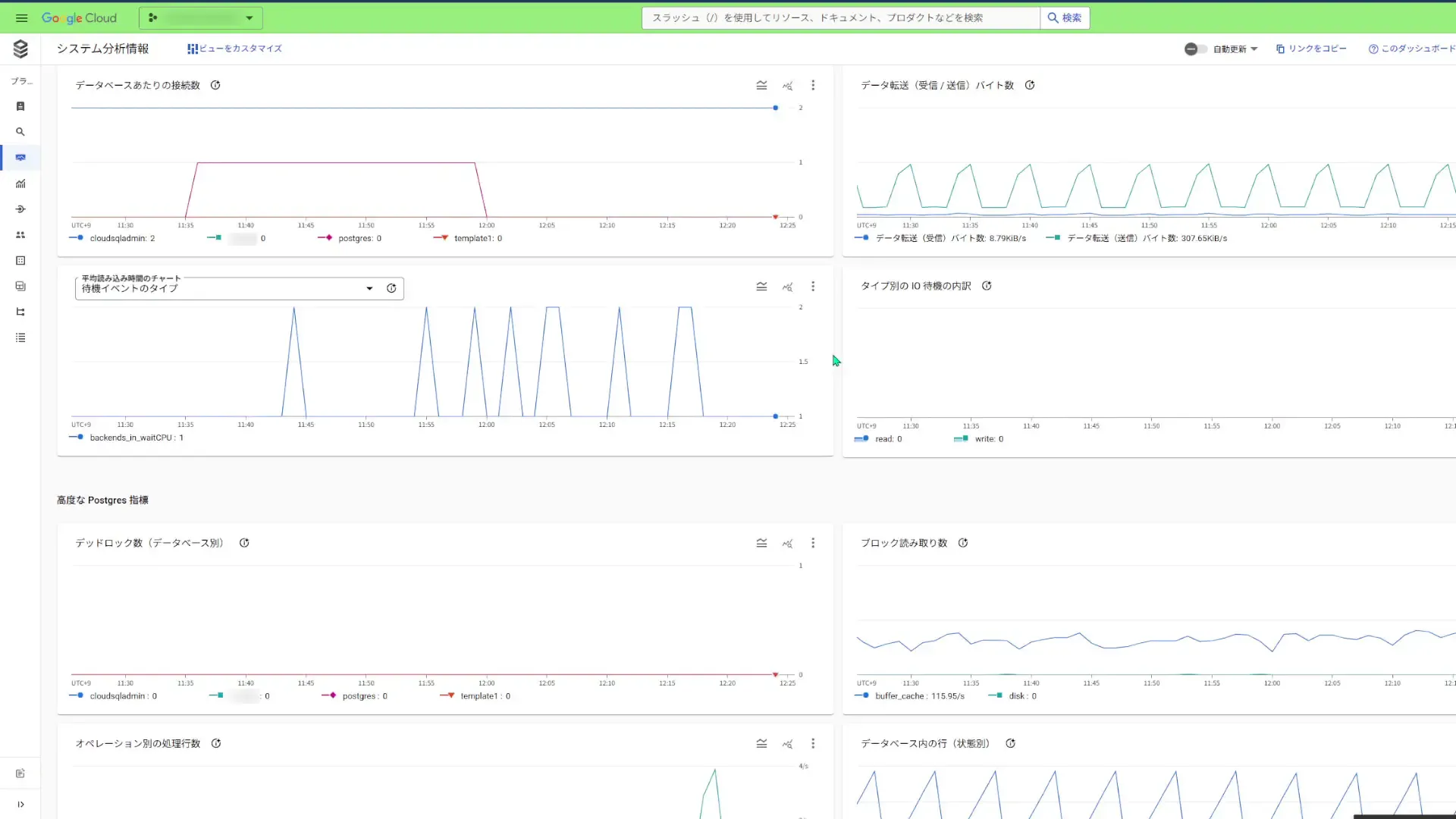
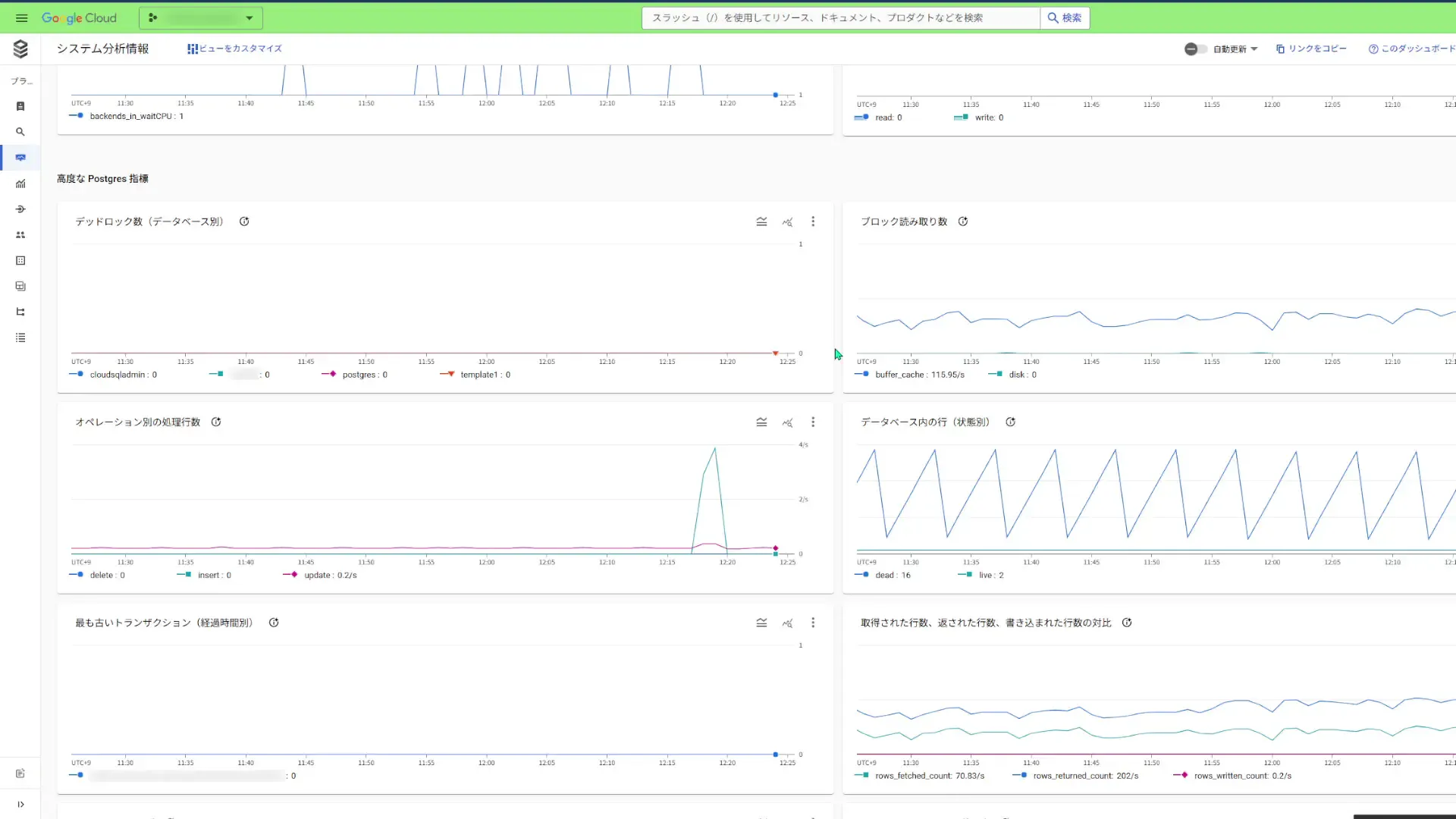
Cloud SQL Studioでテーブルを参照する。
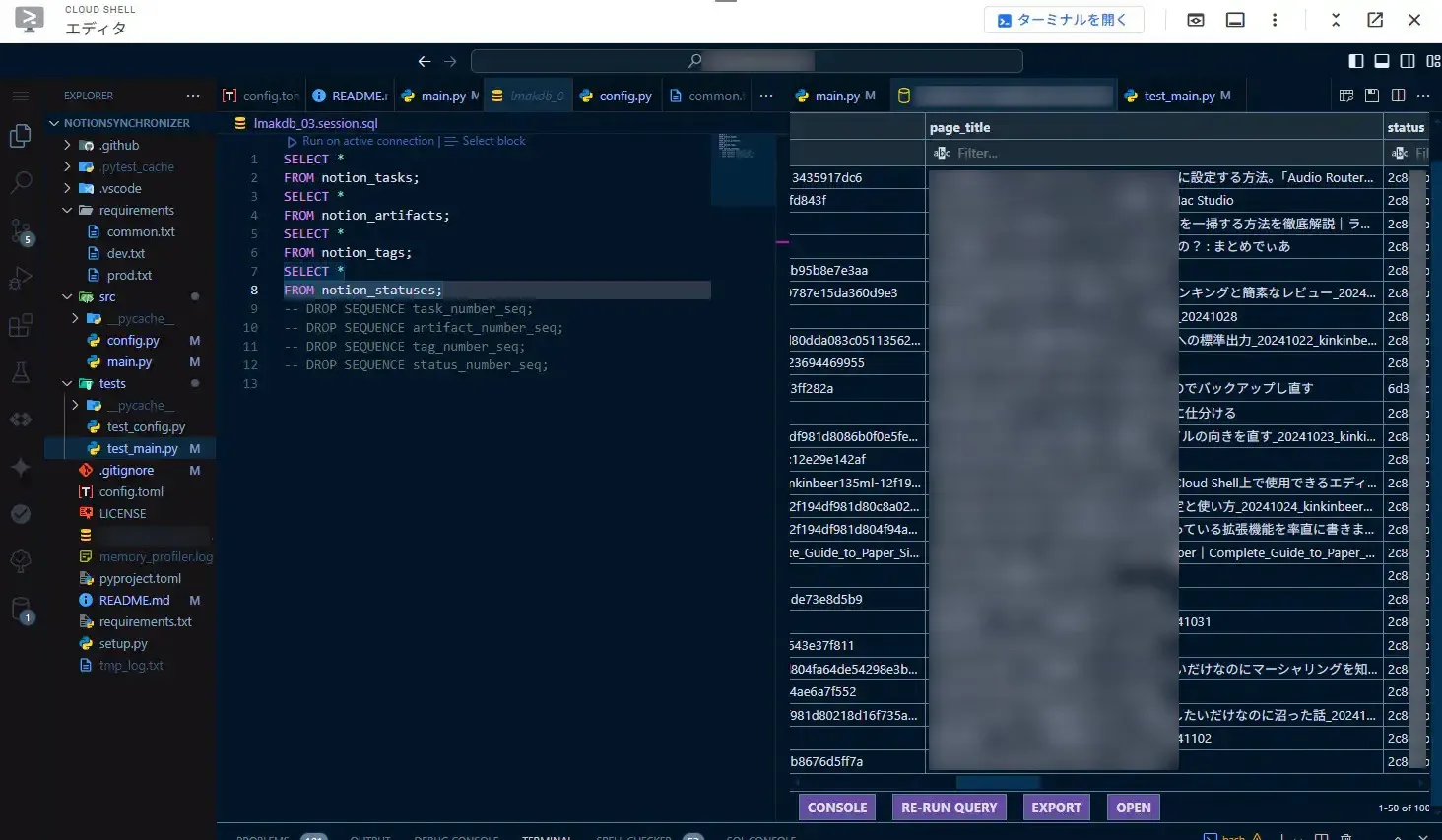
それでは次は、Cloud SQL Studioでテーブルの中身を見ていきます。
Cloud SQLのコンソール上でサイドバーにあるCloud SQL Studioをクリックして開きます。開くとログイン画面になるのでログインして、データベースの中身を確認できるようになります。
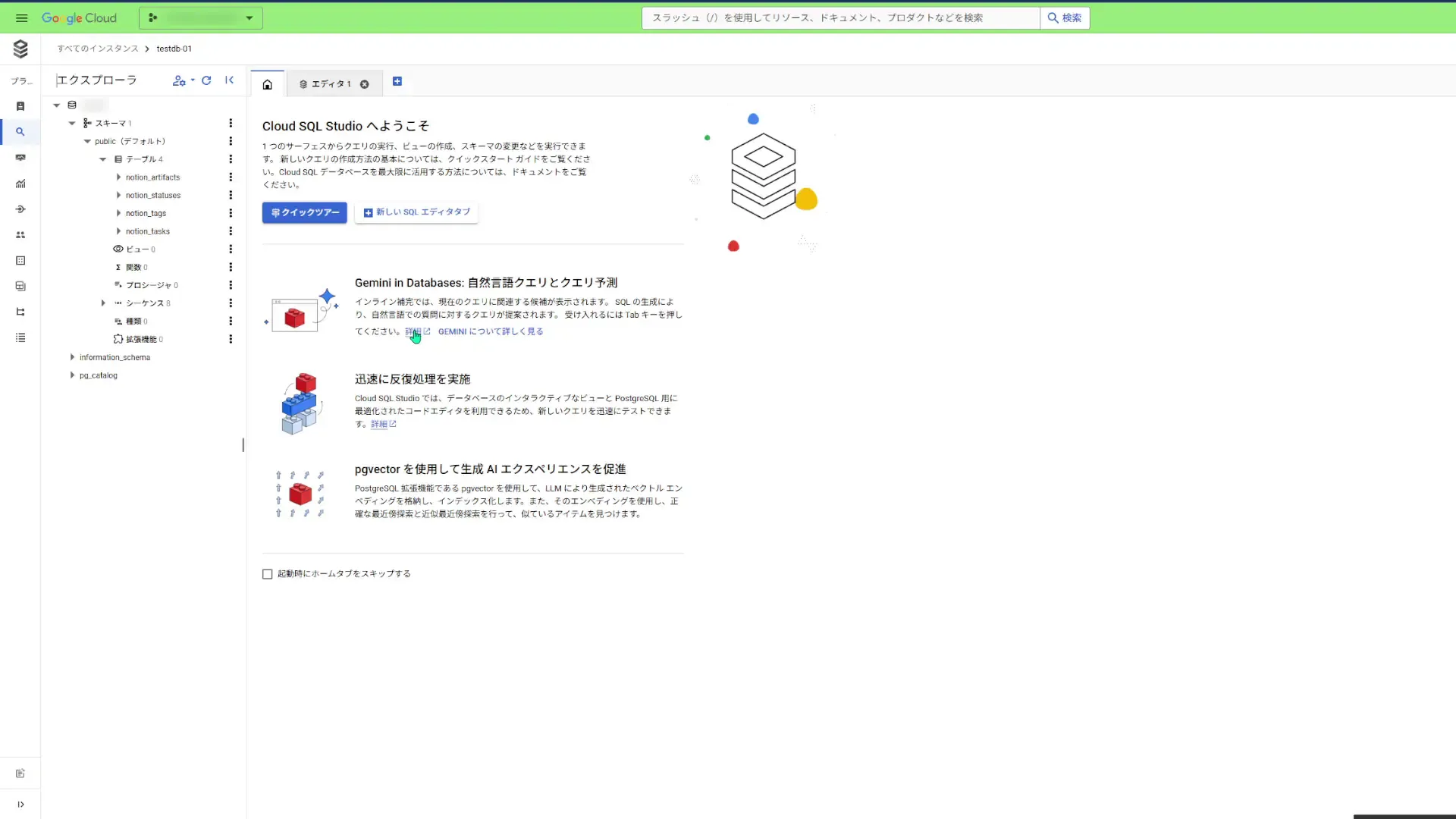
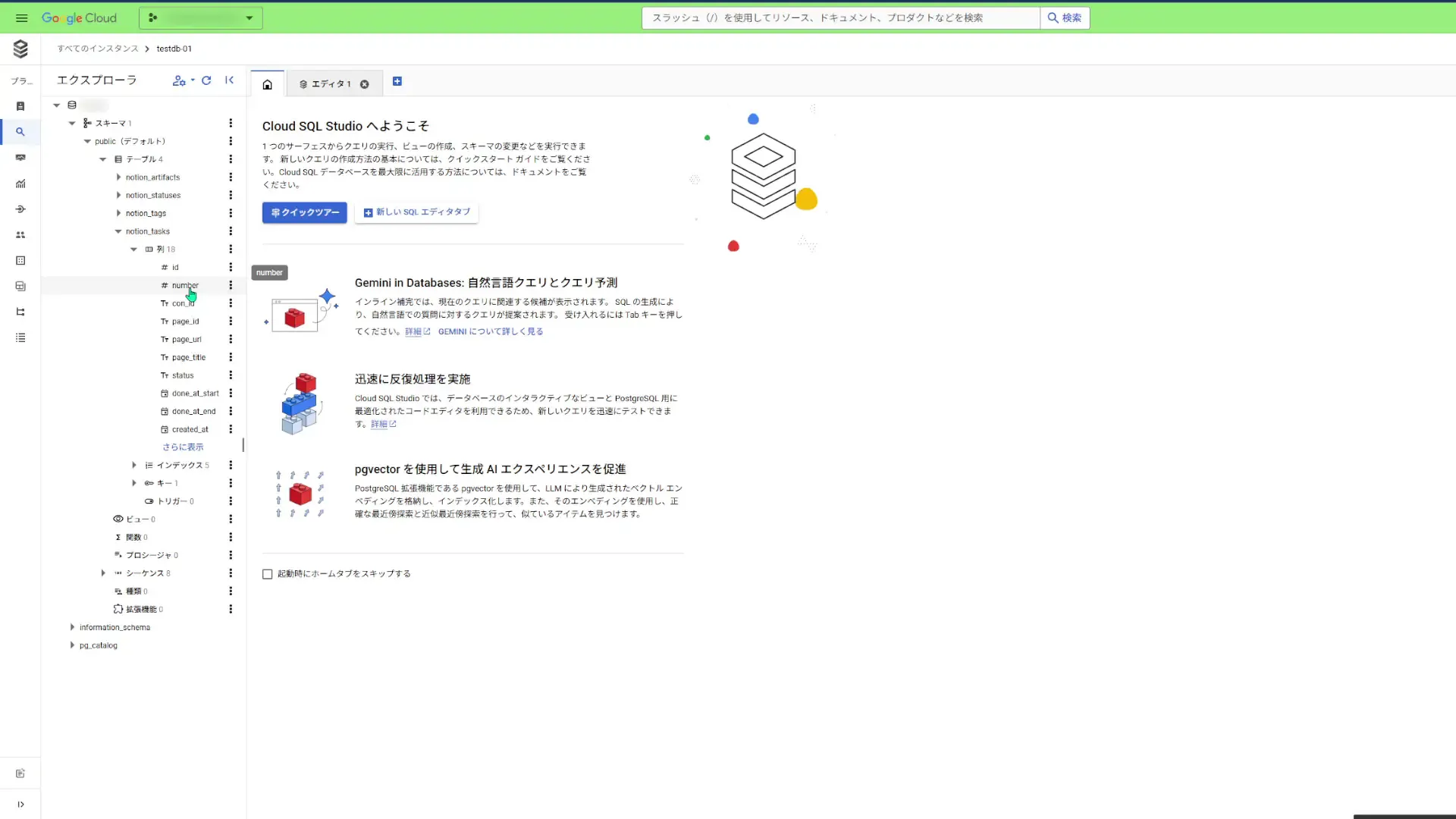
列やシーケンスを確認できます。
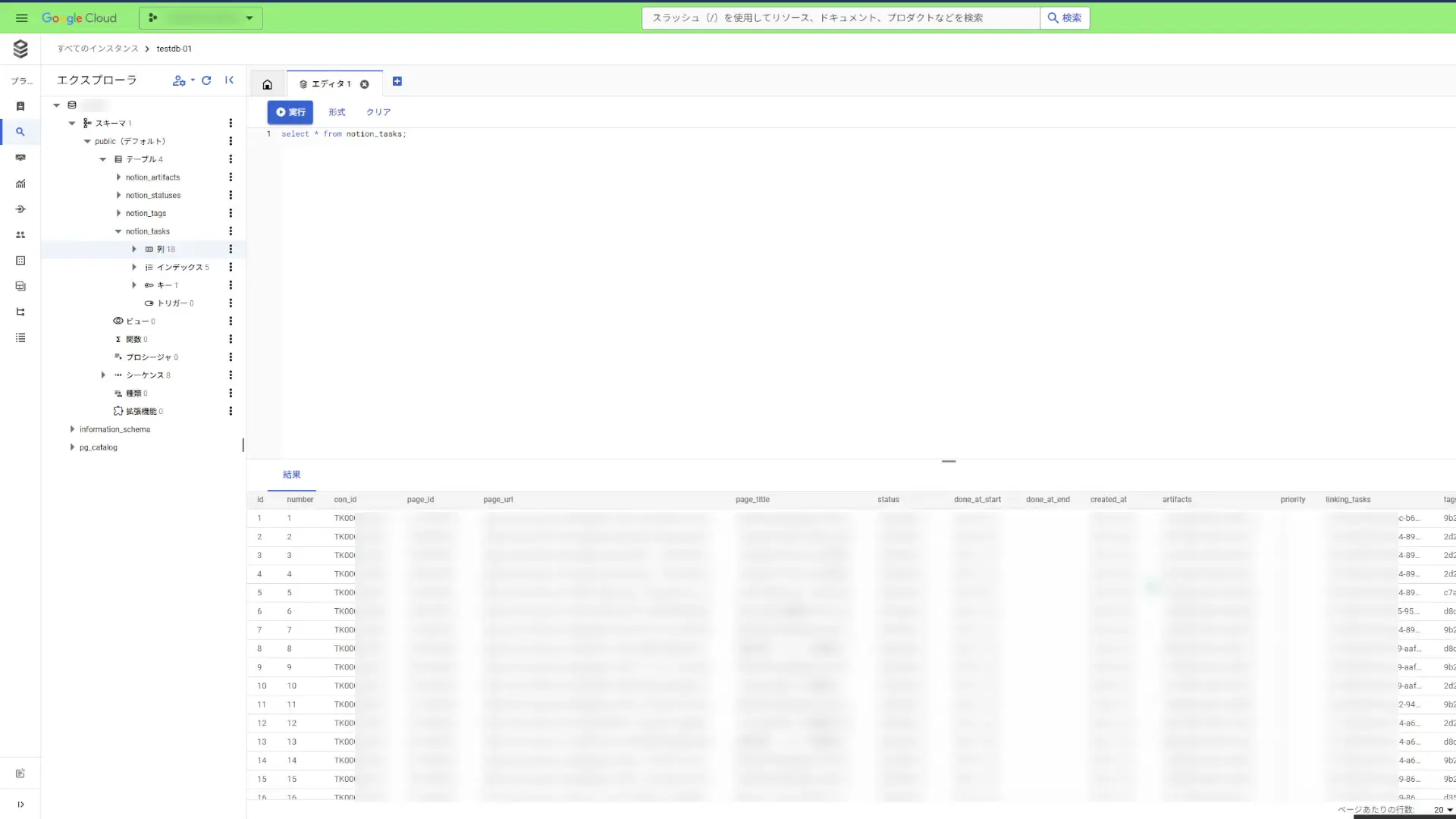
そして、SQLを打ち込めるコンソールもあるので、SELECT文を打てば先程テーブルに格納したレコードを確認することが出来ました。
DBインスタンスを片付ける。
今回、お試しに作っただけなので、課金されないように片付けたいと思います。
インスタンスが不要になったら削除したいところですが、削除する前にインスタンスの削除保護を解除する必要があります。
このインスタンスの削除保護の解除は、インスタンスが起動している間にしか行うことが出来ません。なので、停止する前に設定します。
片付けたいDBインスタンスを表示して編集をクリックします。
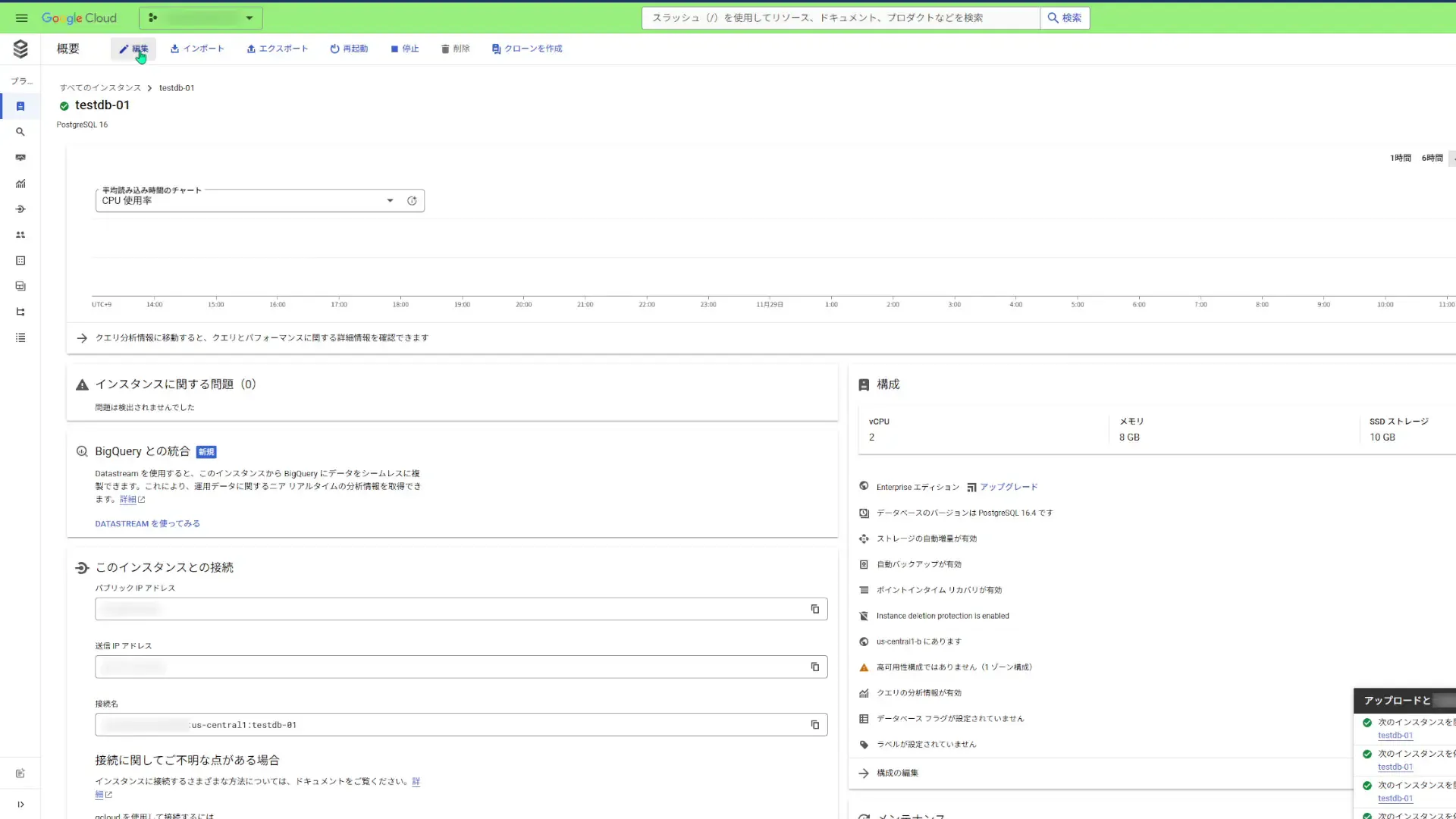
インスタンスのカスタマイズセクションにて、データの保護の項目で、削除からの保護の有効化のチェックボックスをオフにします。
その状態で保存すると、設定したインスタンスを削除できるようになっています。そしたらインスタンスを削除します。
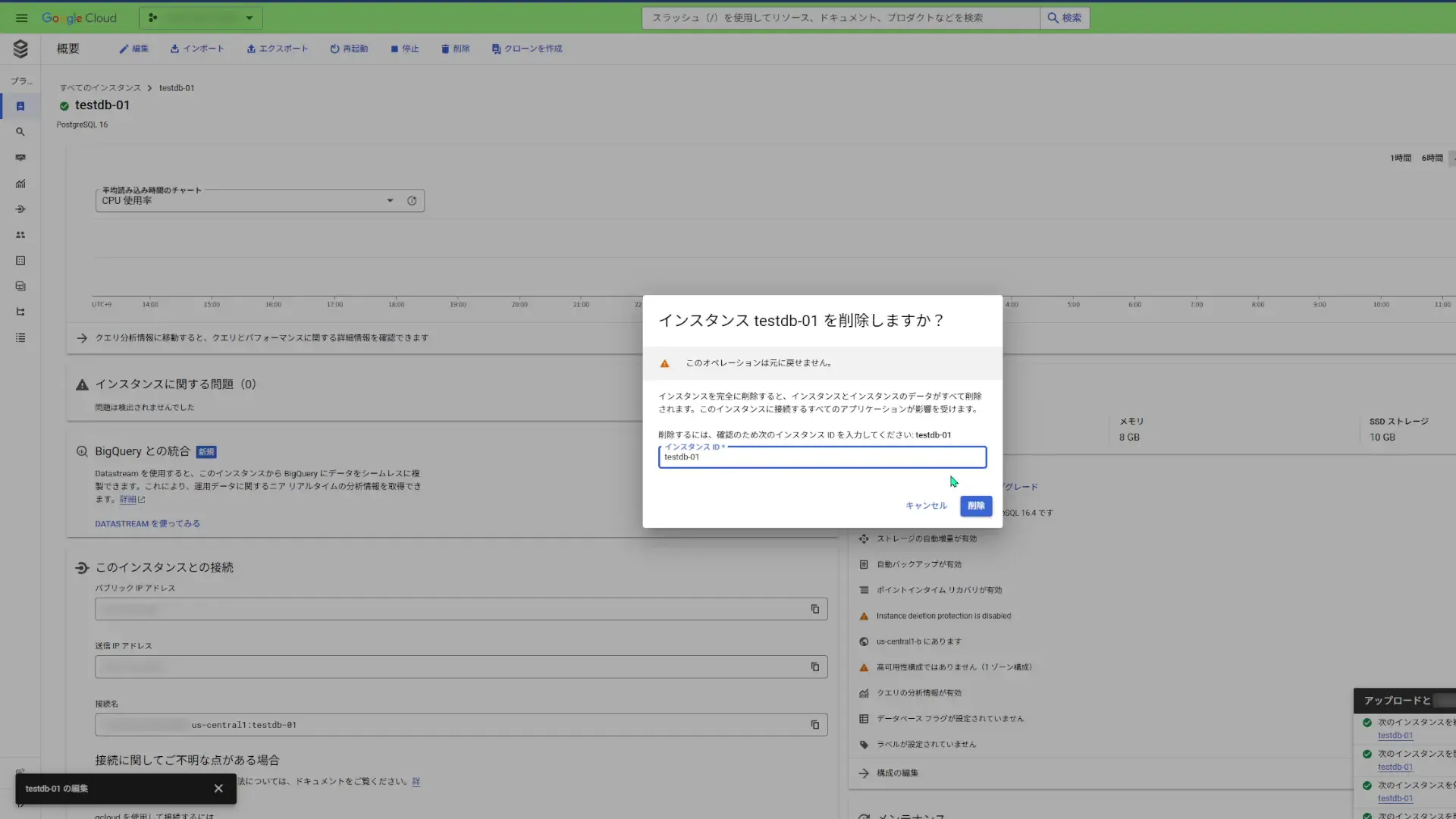
削除できました。削除するのに1分ほど掛かりました。
Cloud FunctionsではCloud SQLを使えない。
今回試しにCloud SQLを使ってみて分かったことは、Cloud FunctionsではCloud SQLを使えないということです。
Cloud SQLがリクエストをListen出来る状態にして、Cloud SQLにアクセス出来るようにしなければなりません。
ということで、今回は一旦ここで切り上げて、第2回で何かしらデプロイした環境からCloud SQLを叩けるようにしたいと思います。
まとめ
今回は、PythonでNotion APIから取得した情報をCloud SQL上に作成したPostgreSQLデータベースに格納する方法を紹介しました。
そして、本記事のまとめです。
- Goは、Notion APIから取得した情報をPostgreSQLに格納するという処理に不向きである。
- SQLAlchemyで一気にInsertできるクエリを作った。
- PostgreSQLのDBに日本語の情報を使う際に、利用するサーバに日本語ロケールを設定する。
- Cloud SQLを利用するために、Cloud SQL Auth Proxy クライアントをインストールすると楽ができる。
- PostgreSQLの仕様で、GRANTで新規ユーザーに何かしらのロールを割り当てないと、そのユーザー用にテーブルを作成できない。
- Cloud SQLのQuery InsightsでDBの状況を確認出来る。
- Cloud SQL Studioでテーブルを参照することが出来る。
SQLAlchemyを使った格納処理が出来てしまえば、Cloud SQLのインスタンスを参照する部分はそこまで大変ではありませんでした。Cloud SQL使いやすかったです。
それから、今回作ったテーブルと同じようなものを再度作ってみて、Cloud SQLにかかる費用を確認してみたいですね・・・。
おしまい
以上になります!
記事を共有
この記事が役に立ったなら、ぜひ他の人と共有してください!
音楽
再生中なし