











【GitHub】PythonとGitHub ActionsでProjectsにIssuesを作る作業を自動化する(前編:Pythonのソース)

はじまり


今回、取り組んだこと
今回は、自分がリポジトリ内に用意したCSVのタイトルと内容を読み取って、その内容をGitHub Projects内にカードとして登録させるツールです。
例えば、このようにCSVを編集しておいて、・・・
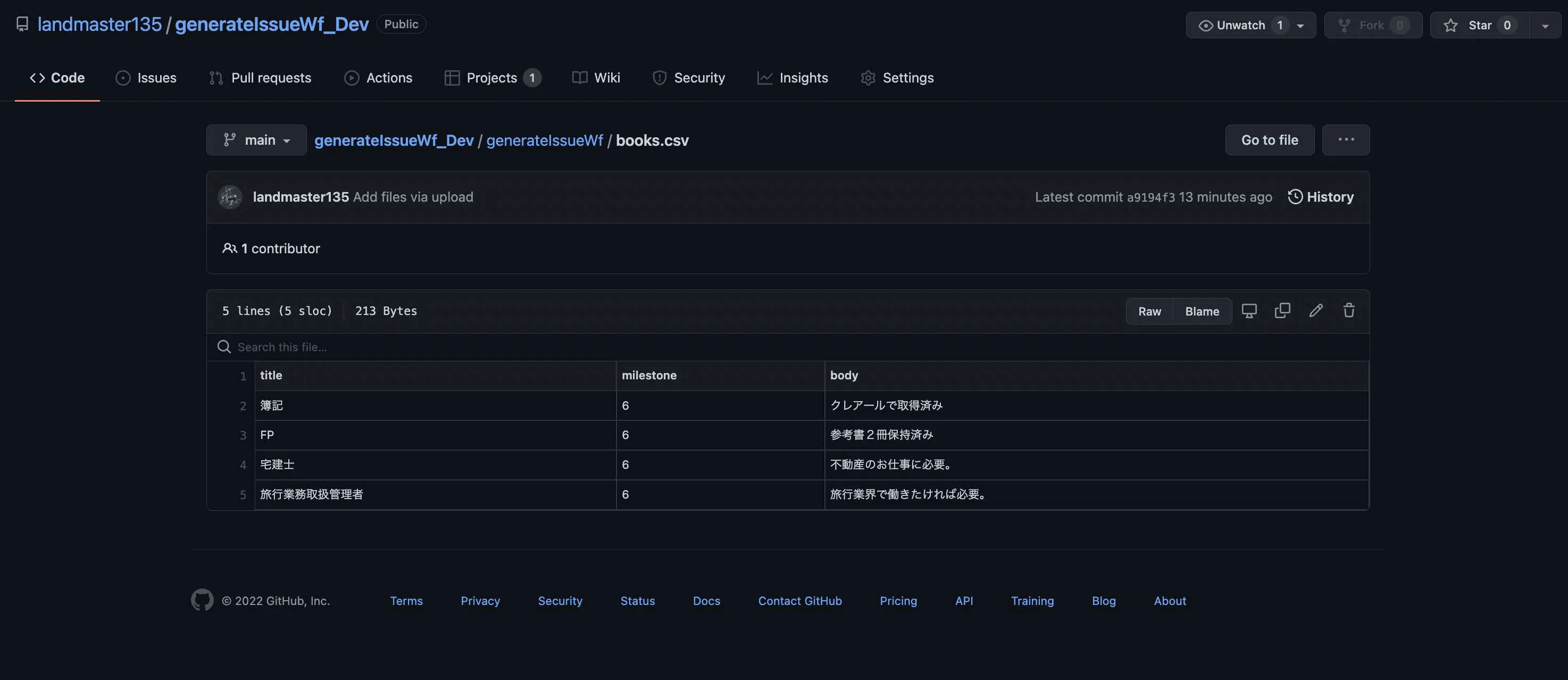
このGitHub Actionsが動くと、CSV内のレコード数と同じ数のワークフローファイルが作成されます。
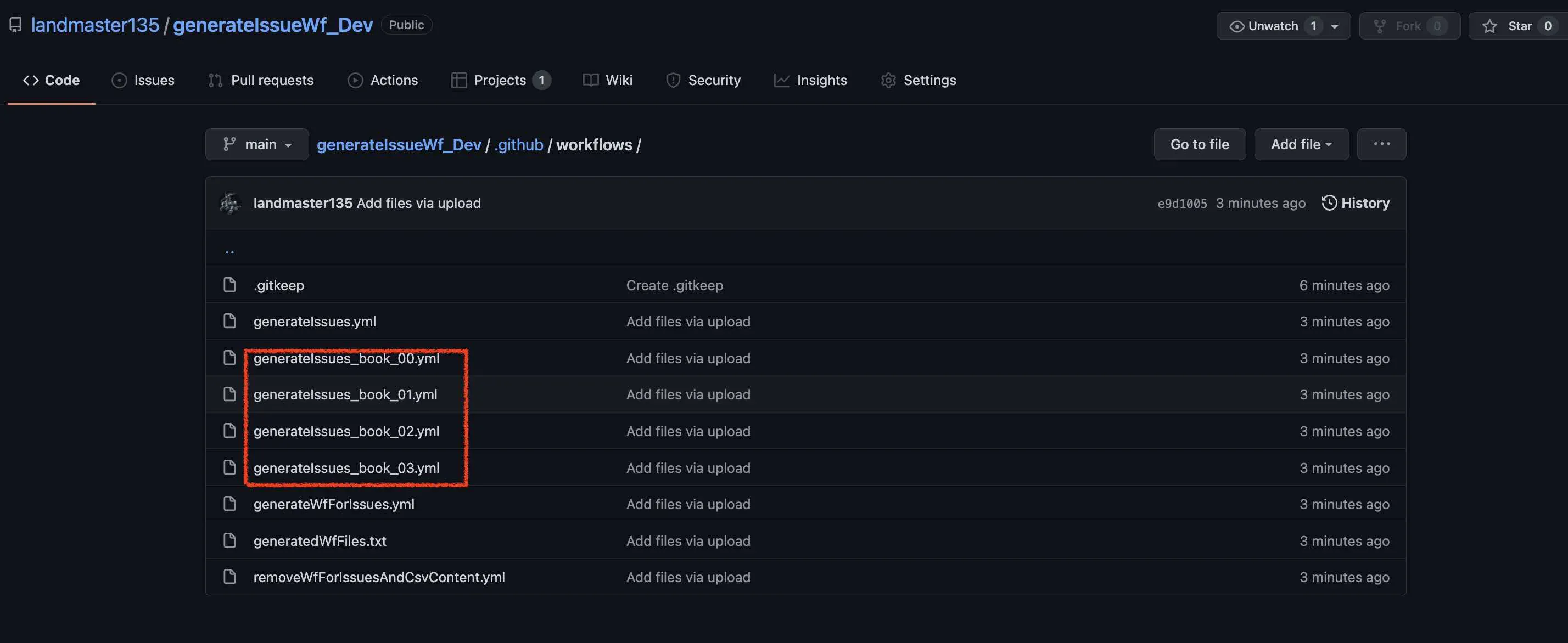
そして、色々動いた後に、このようにkanban形式内でcardが登録されます。Issueも登録されています。
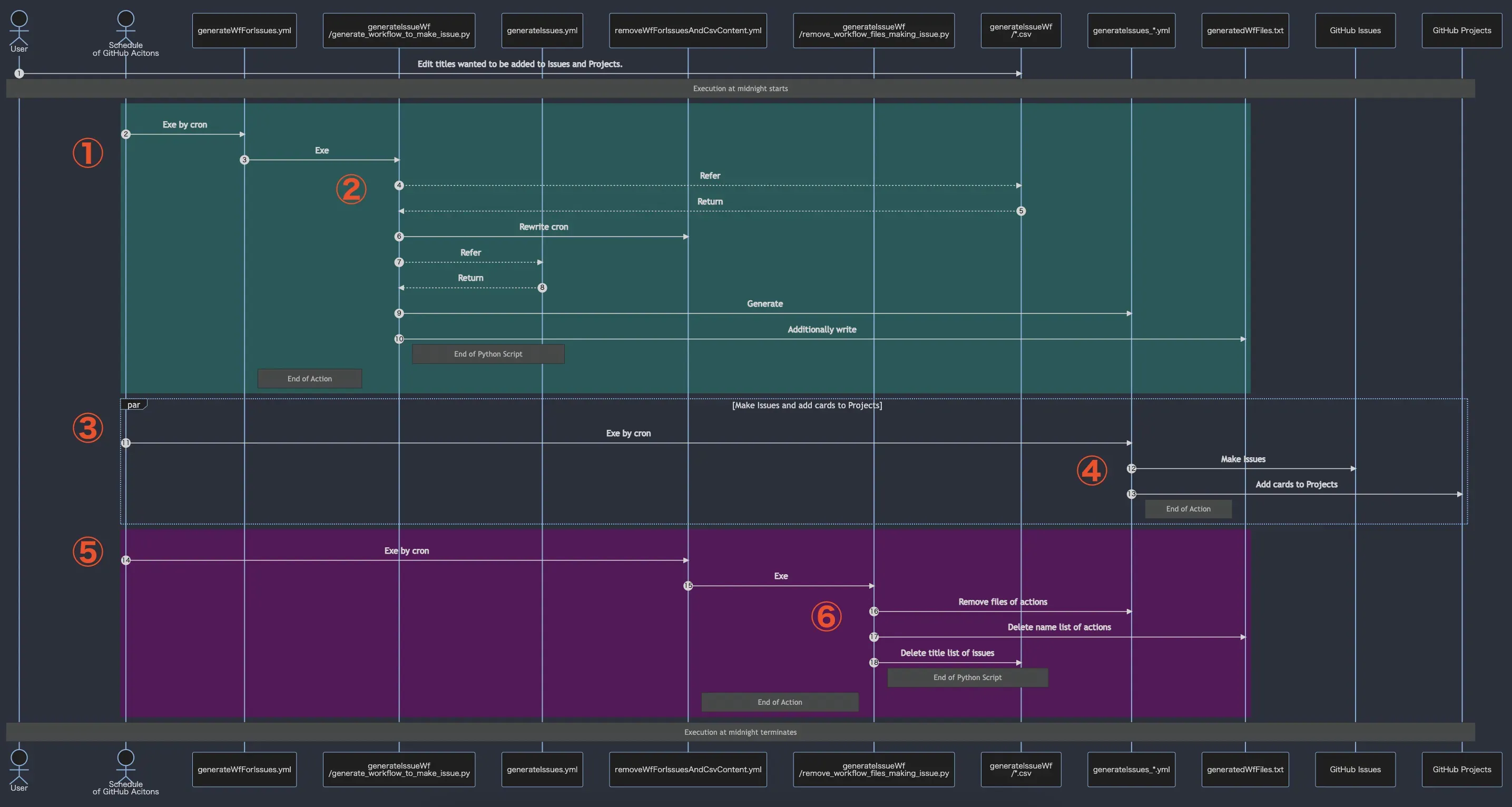
システム構成
ざっと、今回のツールのシステム構成を書きます。
概要図はこんな感じです。
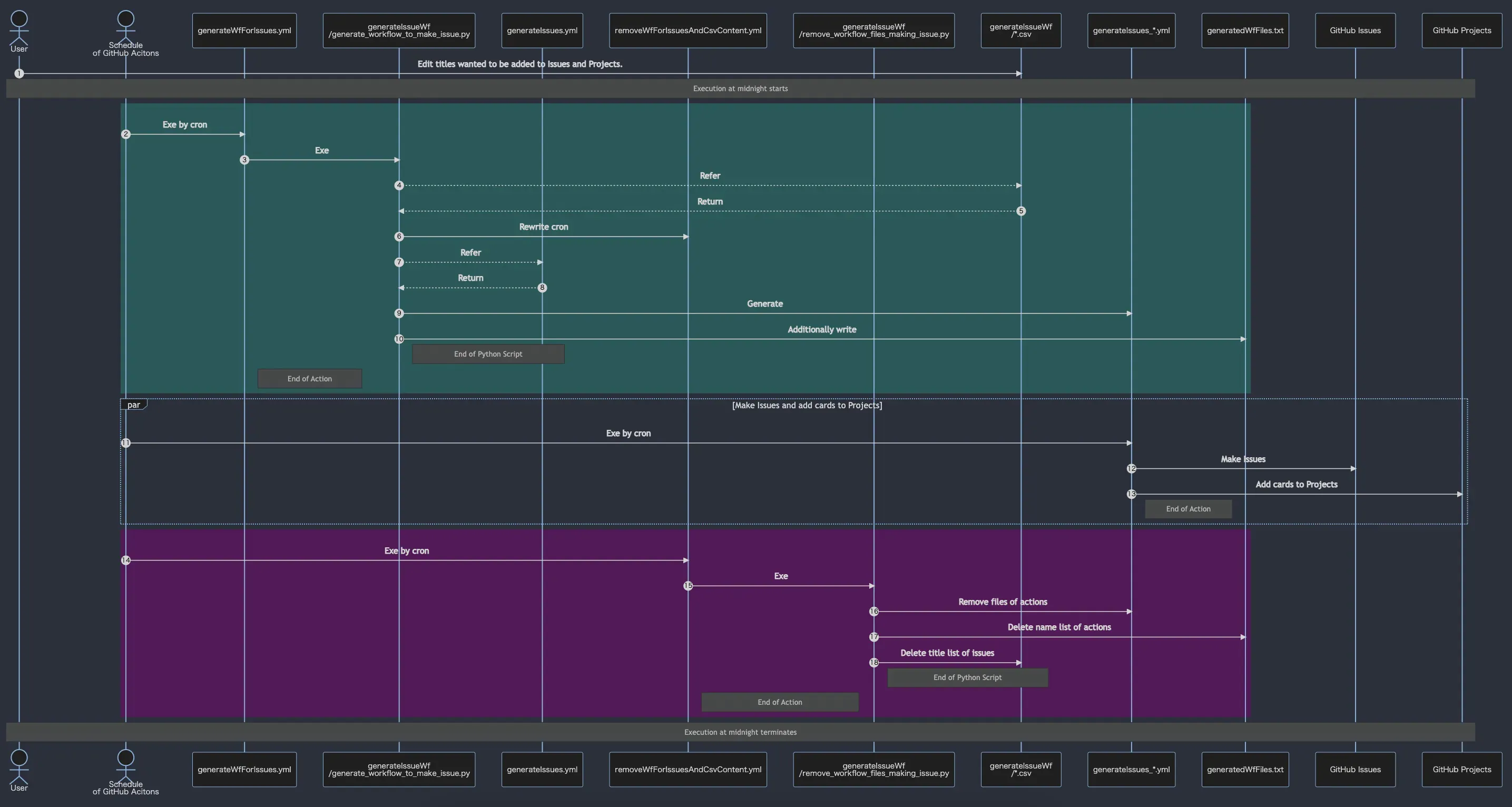
ざっくりした流れは以下の感じです。
- Issueを作るために、Pythonファイルを動かすGitHub Actionsが動く。(夜中の4時に設定)
- Pythonファイルが動いて、Issueを作るためのGitHub Actionsのワークフローファイルが作成される。
- そのワークフローファイルは、そのPythonファイルが動いた10分後に起動する。
- ワークフローファイルが起動。Issueに登録したと同時にGitHub Projectsにもカードを追加する。
- その日に登録した分のワークフローファイルとCSVの内容を削除するために、Pythonファイルを動かすGitHub Actionsが動く。(1. の30分後に設定。設定処理は、2. で行っていた。)
- Pythonファイルが動いて、ワークフローファイルとCSVの内容を削除する。
流れと概要図を対応させるとこんな感じです。
今回作ったツールの肝となるGitHub Actionsがこれです。GitHub公式のものみたいなので、長い期間利用できそうです。
Pythonスクリプトの中身
今回は、前編として、Pythonの中身を見てみたいと思います。
Pythonを実行するディレクトリ内の構成は、以下の感じになっています。img/とREADME.mdは使いません。requirements.txtでは、僕用に色々な処理をまとめたライブラリだけをインストールします。
Pythonファイルその1:generate_workflow_to_make_issue.py
以下がソースです。
# Library by defaultfrom distutils.log import errorfrom time import timeimport tracebackfrom pathlib import Path# Library by third party# nothing# Library in the local# nothing# Library in landmasterlibraryfrom landmasterlibrary.generaltool import get_str_by_zero_padding, get_src_path_from_test_path, read_txt_lines, read_csv_lines, get_indcies_containing_words, append_items, generate_cron_from_datetime_now
def rewrite_cron_of_remove_workflow(is_there_issue_to_generate : bool, minutes_scheduled_later : int, time_difference : int): file_name = "removeWfForIssuesAndCsvContent.yml" dir_having_file = ".github/workflows" file_full_name = get_src_path_from_test_path(__file__, file_name, dir_having_file, isChecking=False)
read_wf_lines = read_txt_lines(__file__, [file_name], dir_having_file)[0] mark_of_schedule = " schedule:" index_of_workflow_schedule = get_indcies_containing_words(read_wf_lines, [mark_of_schedule])[0] mark_of_cron = " - cron: '" index_of_workflow_cron = get_indcies_containing_words(read_wf_lines, [mark_of_cron])[0] cron = generate_cron_from_datetime_now(minutes_scheduled_later, time_difference)
read_wf_lines[index_of_workflow_schedule] = " schedule:" read_wf_lines[index_of_workflow_cron] = f" - cron: '{cron}' # https://crontab.guru"
read_wf_lines_str = "\n".join(map(str, read_wf_lines)) with open(file_full_name, "w") as fw: fw.write(read_wf_lines_str) print(read_wf_lines_str) print("==================================")
def generate_workflow(): labels = ["book", "blog"] read_files = [] count_of_zero_length = 0 is_there_issue_to_generate = True for i in range(0, len(labels)): read_files.append(f"{labels[i]}s.csv") txt_lines = read_csv_lines(__file__, read_files, "generateIssueWf") for i in range(0, len(txt_lines)): txt_lines[i].pop(0) # remove "title,milestone" row. if len(txt_lines[i]) == 0: count_of_zero_length += 1 print(txt_lines)
if count_of_zero_length == len(labels): txt_lines = [[["dummytitle", 0, "dummybody"]]] is_there_issue_to_generate = False
minutes_scheduled_later = 10 time_difference = 0 cron = generate_cron_from_datetime_now(minutes_scheduled_later, time_difference) rewrite_cron_of_remove_workflow(is_there_issue_to_generate, minutes_scheduled_later + 20, time_difference)
cron_lines = [] if is_there_issue_to_generate: cron_lines.append(" schedule:") cron_lines.append(f" - cron: '{cron}' # https://crontab.guru") else: cron_lines.append("# schedule:") cron_lines.append(f"# - cron: '{cron}' # https://crontab.guru") print("No generated workflows to make issues today.") # return False
str_of_workflow_dispatch = " workflow_dispatch:" read_wf_lines = read_txt_lines(__file__, ["generateIssues.yml"], ".github/workflows")[0] index_of_workflow_dispatch = read_wf_lines.index(str_of_workflow_dispatch) read_wf_lines = append_items(read_wf_lines, cron_lines, index_of_workflow_dispatch + 1)
str_of_scheduled_issue = " - name: Scheduled Issue to landmaster135" index_of_name_of_scheduled_issue = read_wf_lines.index(str_of_scheduled_issue)
src_file_name = "generateIssues.yml" generated_files = [] for i in range(0, len(txt_lines)): for j in range(0, len(txt_lines[i])): # write contents read_wf_lines[index_of_name_of_scheduled_issue + 3] = f" title: {txt_lines[i][j][0]}" # title label = str(labels[i]) read_wf_lines[index_of_name_of_scheduled_issue + 5] = f" labels: \"{label}\"" # labels read_wf_lines[index_of_name_of_scheduled_issue + 8] = f" template: \".github/ISSUE_TEMPLATE/custom.md\"" # template read_wf_lines[index_of_name_of_scheduled_issue + 9] = f" project: 1" # project read_wf_lines[index_of_name_of_scheduled_issue + 10] = f" column: Todo" # column milestone = "" initial_of_milestone = " milestone: " if txt_lines[i][j][1] == "0": pass else: milestone = f"{initial_of_milestone}{str(txt_lines[i][j][1])}" read_wf_lines[index_of_name_of_scheduled_issue + 11] = milestone # milestone read_wf_lines[index_of_name_of_scheduled_issue + 12] = f" body: {txt_lines[i][j][2]}" # body
# decide file name j_padded = get_str_by_zero_padding(j, 2) src_file_name = f"generateIssues_{label}_{j_padded}.yml" generated_file_full_name = get_src_path_from_test_path(__file__, src_file_name, ".github/workflows", isChecking=False)
# generate workflow files read_wf_lines_str = "\n".join(map(str, read_wf_lines)) with open(generated_file_full_name, "w") as fw: fw.writelines(read_wf_lines_str) generated_files.append(src_file_name)
# genereate text memo file. generated_files_str = "\n".join(map(str, generated_files)) file_name_written_file_to_remove = "generatedWfFiles.txt" generated_file_full_name = get_src_path_from_test_path(__file__, file_name_written_file_to_remove, ".github/workflows", isChecking=False) with open(generated_file_full_name, "w") as fw: fw.write(generated_files_str) for i in read_wf_lines: print(i)
return True
def main(): generate_workflow()
if __name__ == "__main__": main()処理の流れとしては、
- Pythonファイル内で読み取るラベルを指定。今回は、
bookとblog。 - ラベルに対応したCSVファイルを読み取る。今回で言うと、
books.csvとblogs.csvを読み取る。 - issueを登録するワークフローファイルのcronを実行時の10分後に設定する。(まだファイル生成は行わない。)
- もう一つのPythonファイル(
remove_workflow_files_making_issue.py:登録したIssueの元情報(CSVとかワークフローファイル)を消すためのファイル)を実行するワークフローファイルのcronを3.の20分後に設定する。こっちはここでファイル編集を行う。 - 登録したいissueがCSVになかったら、ワークフローファイル用にダミーの内容を1つ用意する。
- 登録する個々のIssueに対して、色々なオプションを設定して、設定するためのワークフローファイルを作成する。
それでは、以下で詳しく解説していきます。
1.Pythonファイル内で読み取るラベルを指定。
今回は、bookとblogを指定したので、books.csvとblogs.csvを作成しておいて、Pythonファイルに読み取らせます。
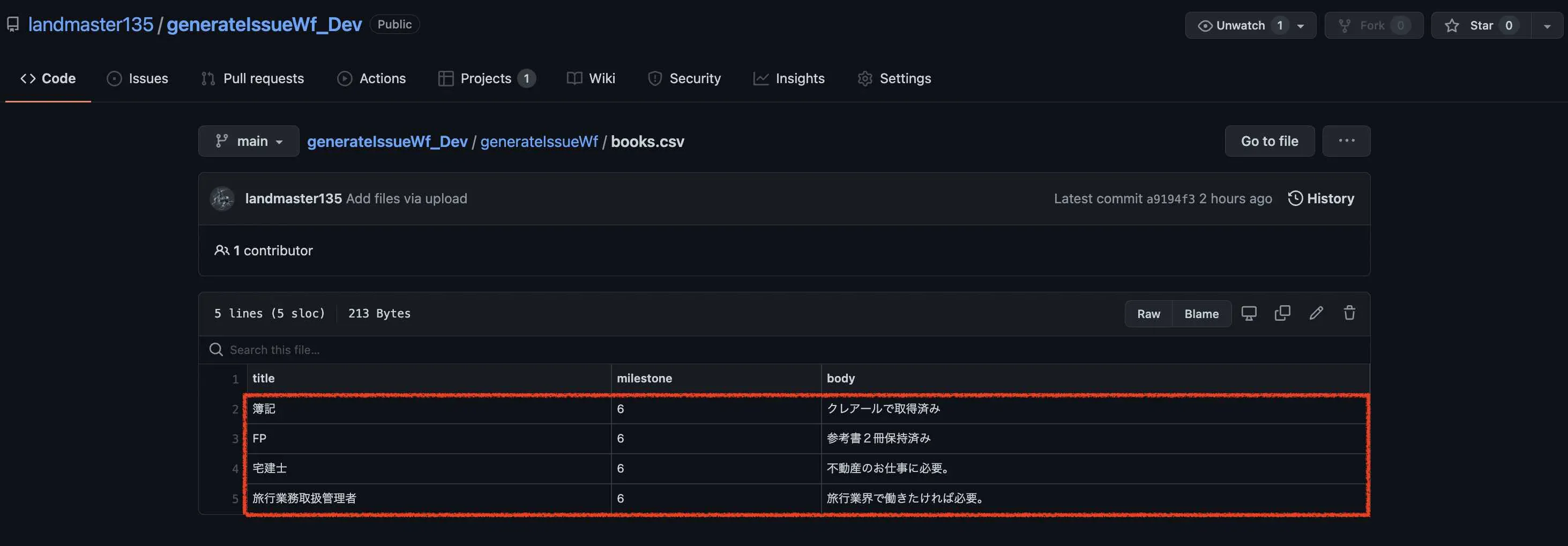
2.ラベルに対応したCSVファイルを読み取る。
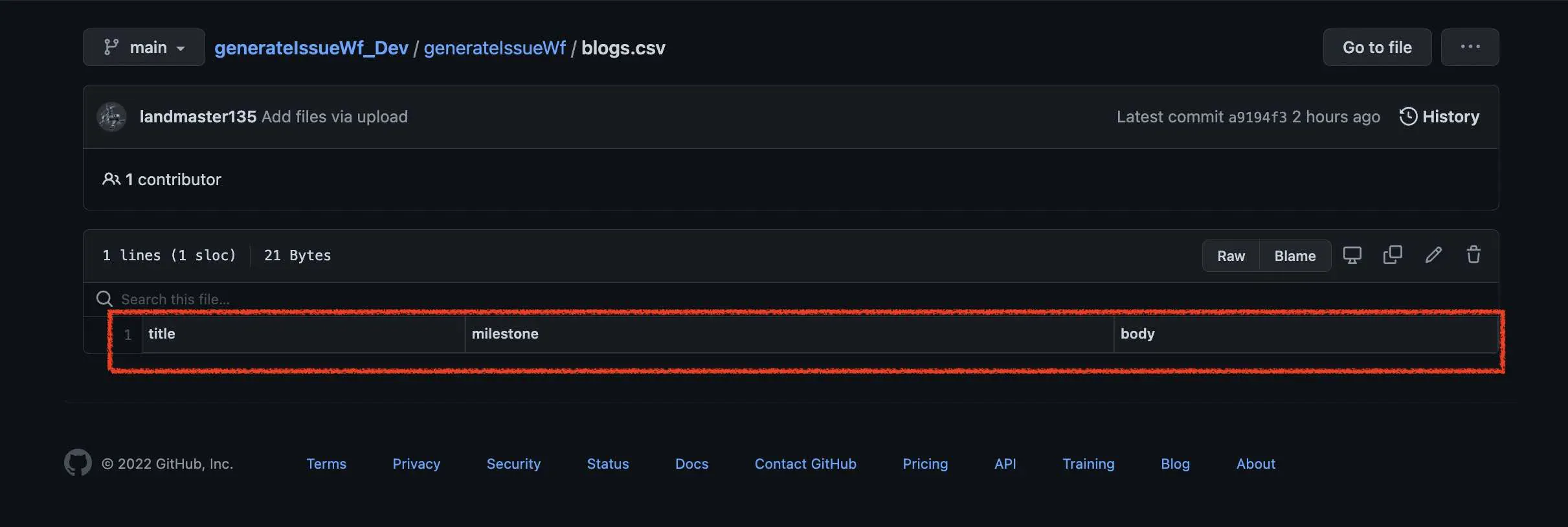
次に、CSVファイルを読み取ります。取得する内容は、ヘッダーの行以外になります。
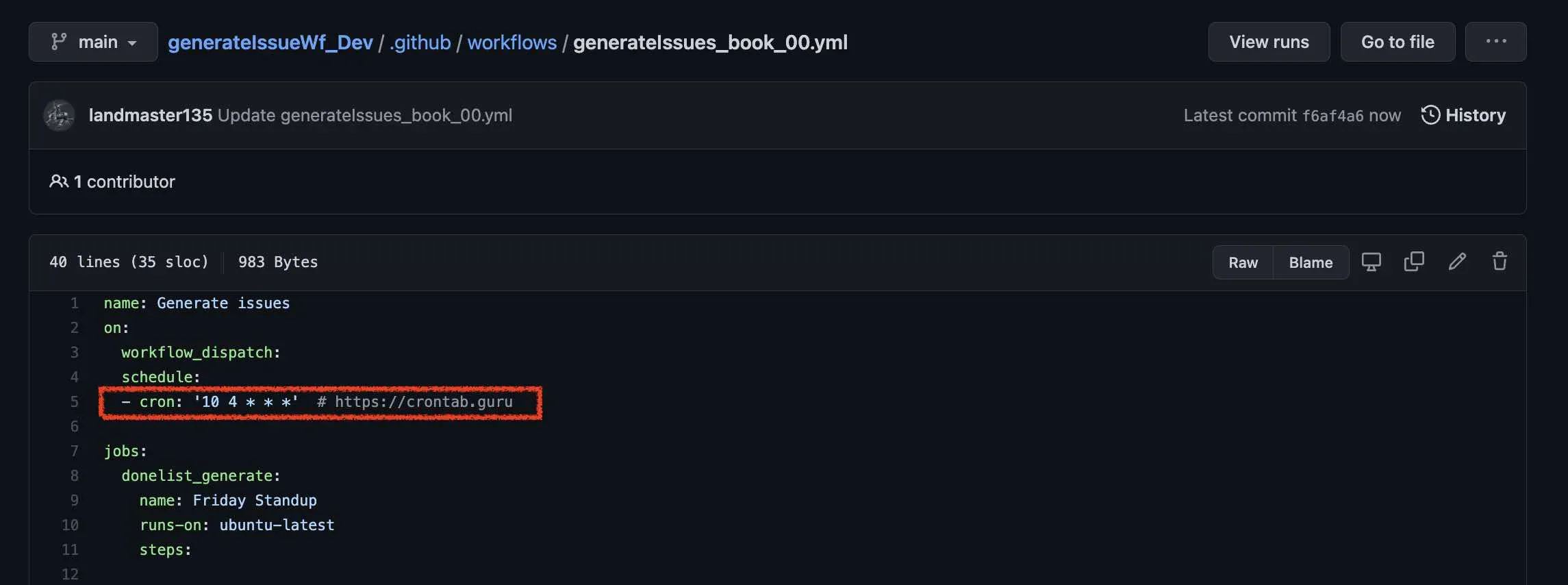
3.issueを登録するワークフローファイルのcronを実行時の10分後に設定する。
これらのIssueを登録するためのワークフローの実行時間を設定します。
ワークフローファイルを作った直後はこんなファイル構成になります。(この工程ではまだ作りません。5.の工程での判定を超えてから作ります。)
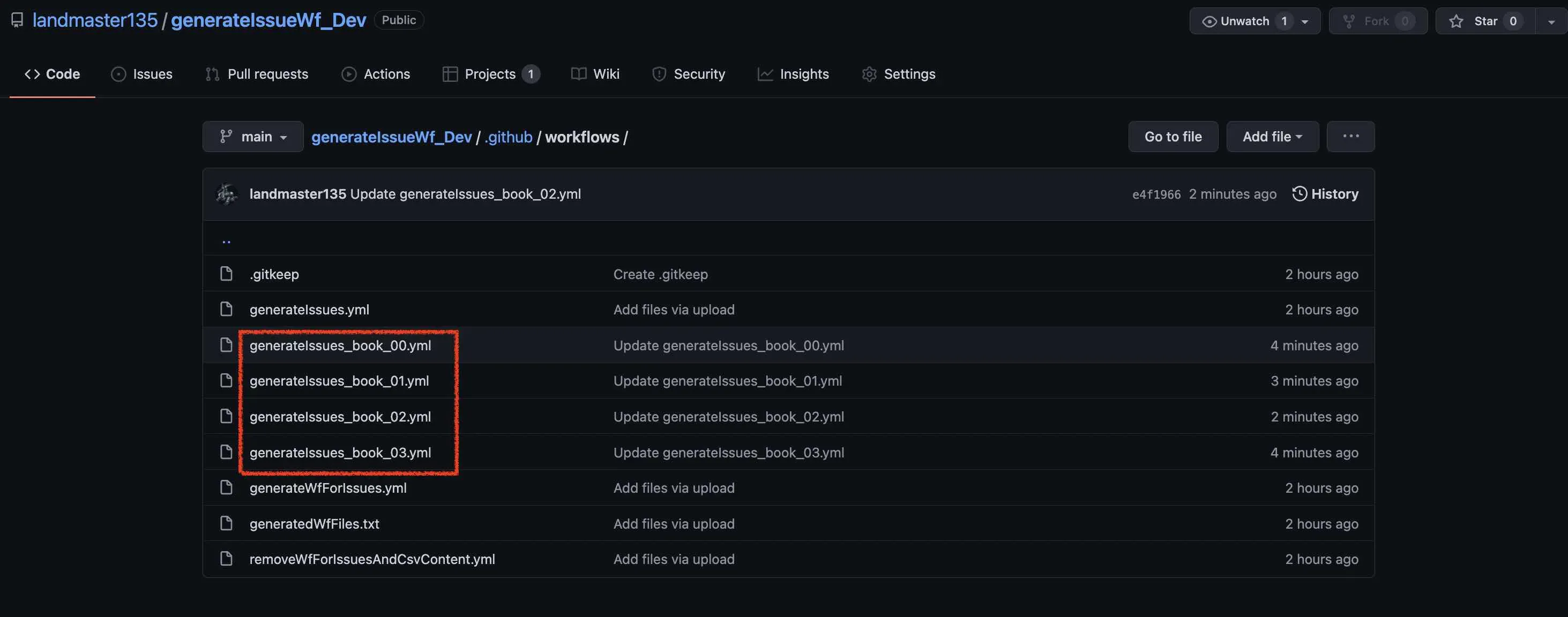
これらのワークフローファイルにcronを設定します。例えば、AM4:00にこのPythonスクリプトが実行されたら、AM4:10にこれらのワークフローファイルが実行されるように設定します。
cron設定の詳細は、この記事でも紹介していますので、よければご参考ください。

4.もう一つのPythonファイルを実行するワークフローファイルのcronを3.の20分後に設定する。
次に、remove_workflow_files_making_issue.pyという、登録したIssueの元情報(CSVとかワークフローファイル)を消すためのPythonファイルを実行するワークフローファイルのスケジュールを設定します。
そのワークフローファイルの名前が、removeWfForIssuesAndCsvContent.ymlと言います。
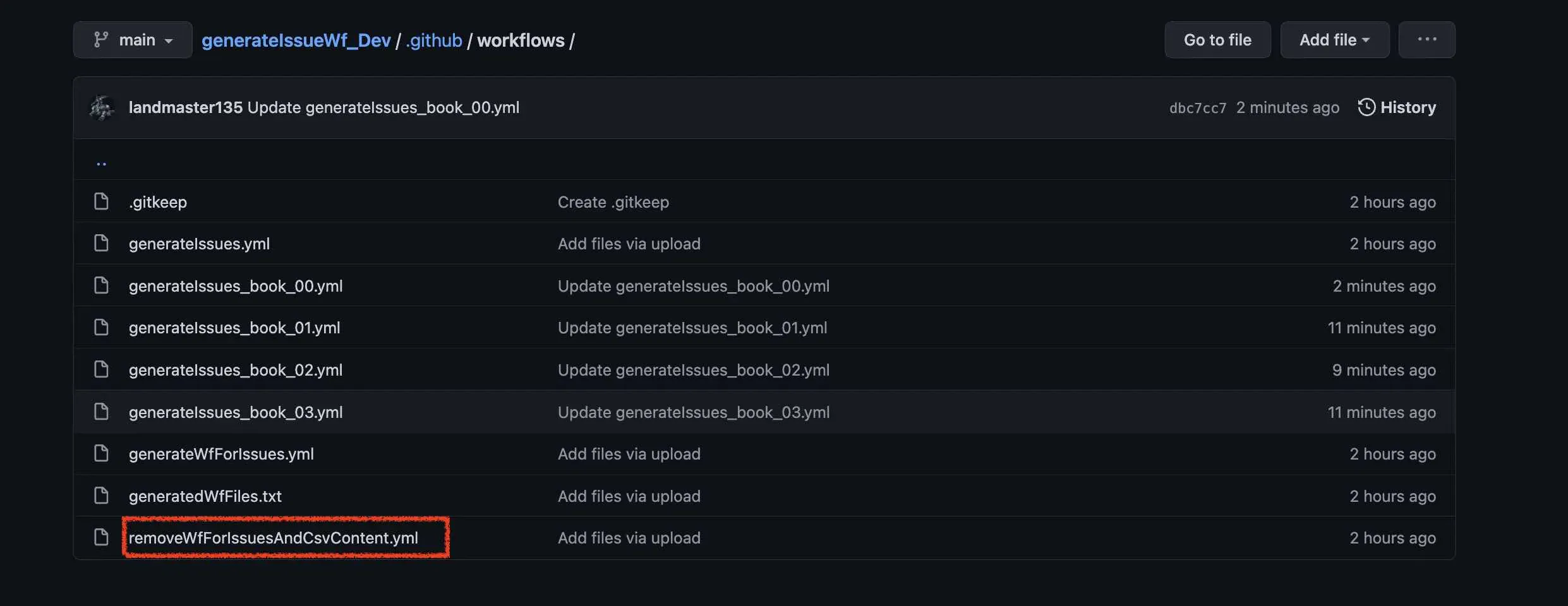
このワークフローファイルにcronを設定します。 例えば、AM4:00にこのPythonスクリプトが実行されたら、先程はAM4:10にこれらのワークフローファイルが実行されるように設定しましたが、
このファイルでは、AM4:30に実行されるように設定します。
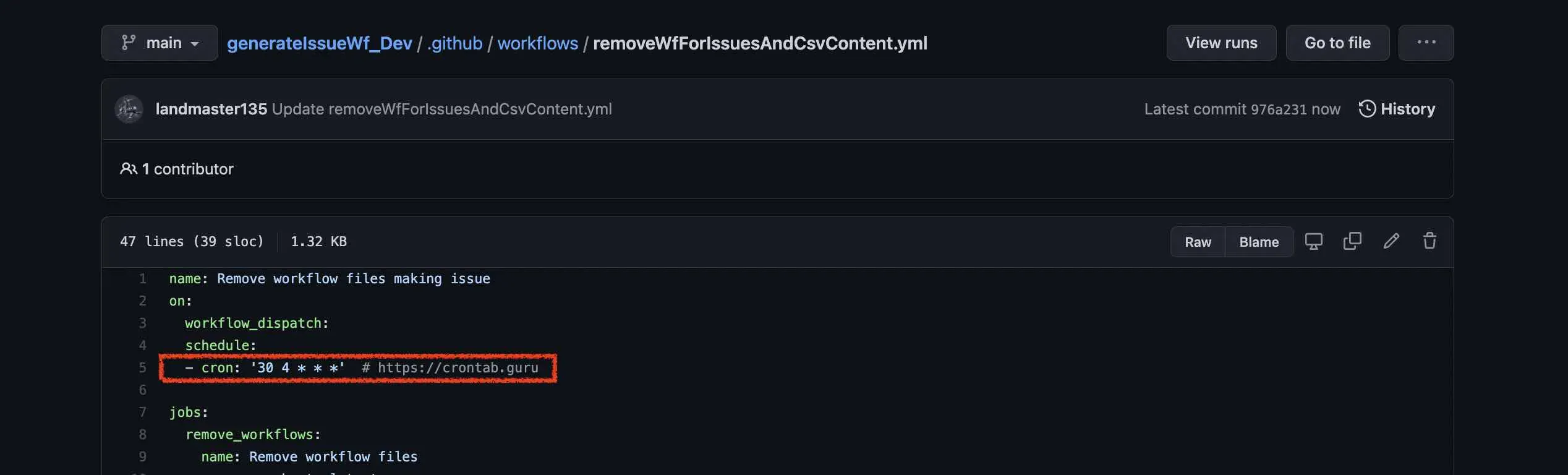
先程も含めて、10分と20分と間を空けていますが、この時間に特別な意味はありません。大体、そのくらいの時間でGitHub Actionsが終わるだろうという見込みの数値です。
5.登録したいissueがCSVになかったら、ダミーの内容でワークフローファイルを1つ作成する。
日によっては、登録したいissueが無いことがあると思います。その場合は、ダミーの内容で、6.の処理を行います。
元々は、6.の処理を行わずに、Pythonスクリプトを終了させるようにしていたのですが、そうするとgit addする際にファイルがないので、GitHub Actions実行中にエラーが発生します。
continue-on-error: trueにして、GitHub Actionsのエラーを無視することも試したのですが、エラーが起きた旨の通知メールは届いてしまうので、git addを空振りさせない方法に落ち着きました。
これがそのメール。これが毎日届くのは煩わしい・・・。
6.登録する個々のIssueに対して、色々なオプションを設定して、設定するためのワークフローファイルを作成する。
5.の壁を超えたら、Issueを設定するためのワークフローファイルを作成する処理に入ります。
作成するための元のワークフローファイルgenerateIssues.ymlを読み取ってそのオプション値を変えていきます。
まず、Issue、ProjectおよびMarkdownテンプレートがある画面と照らし合わせてみてみます。
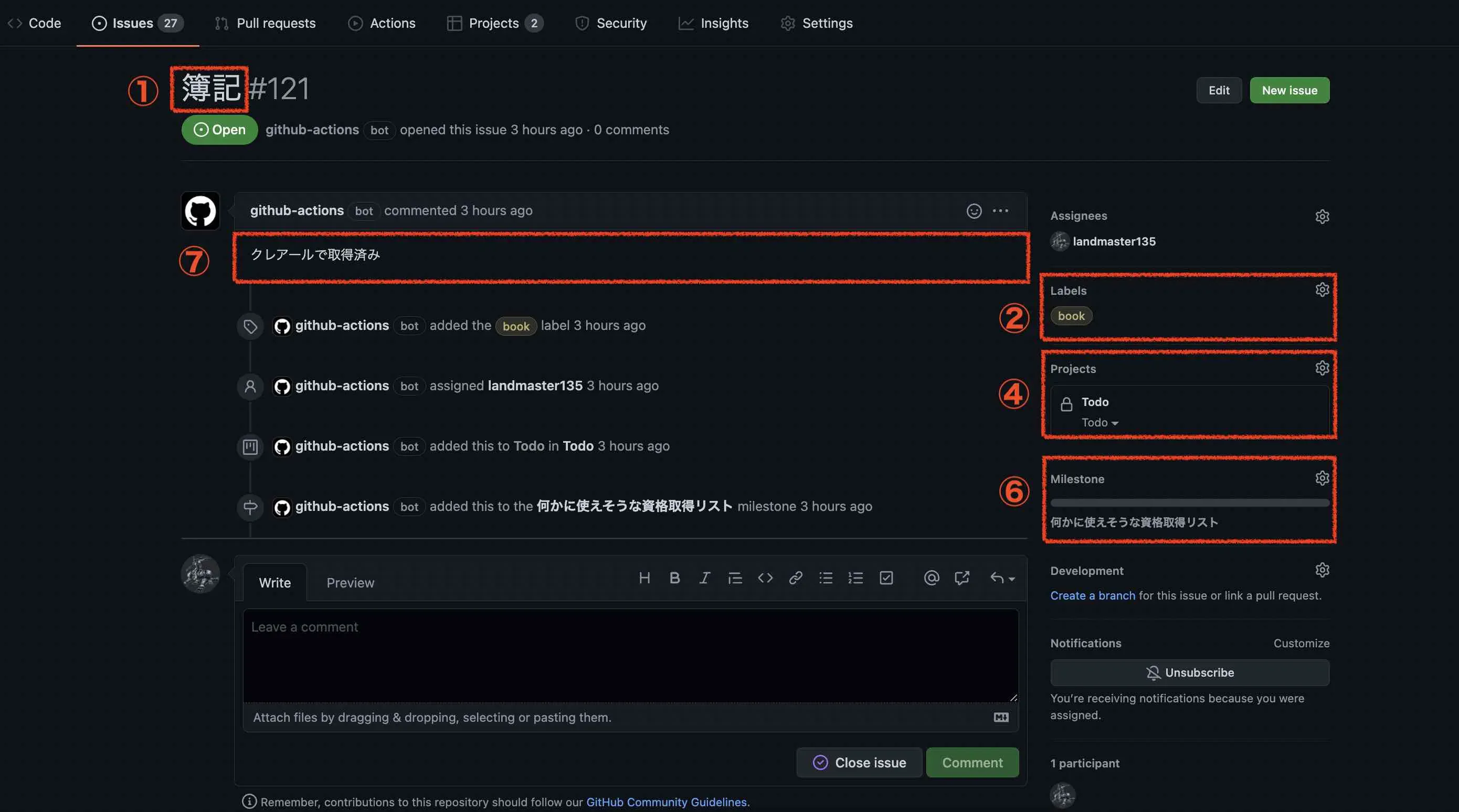
これがIssueのページになります。
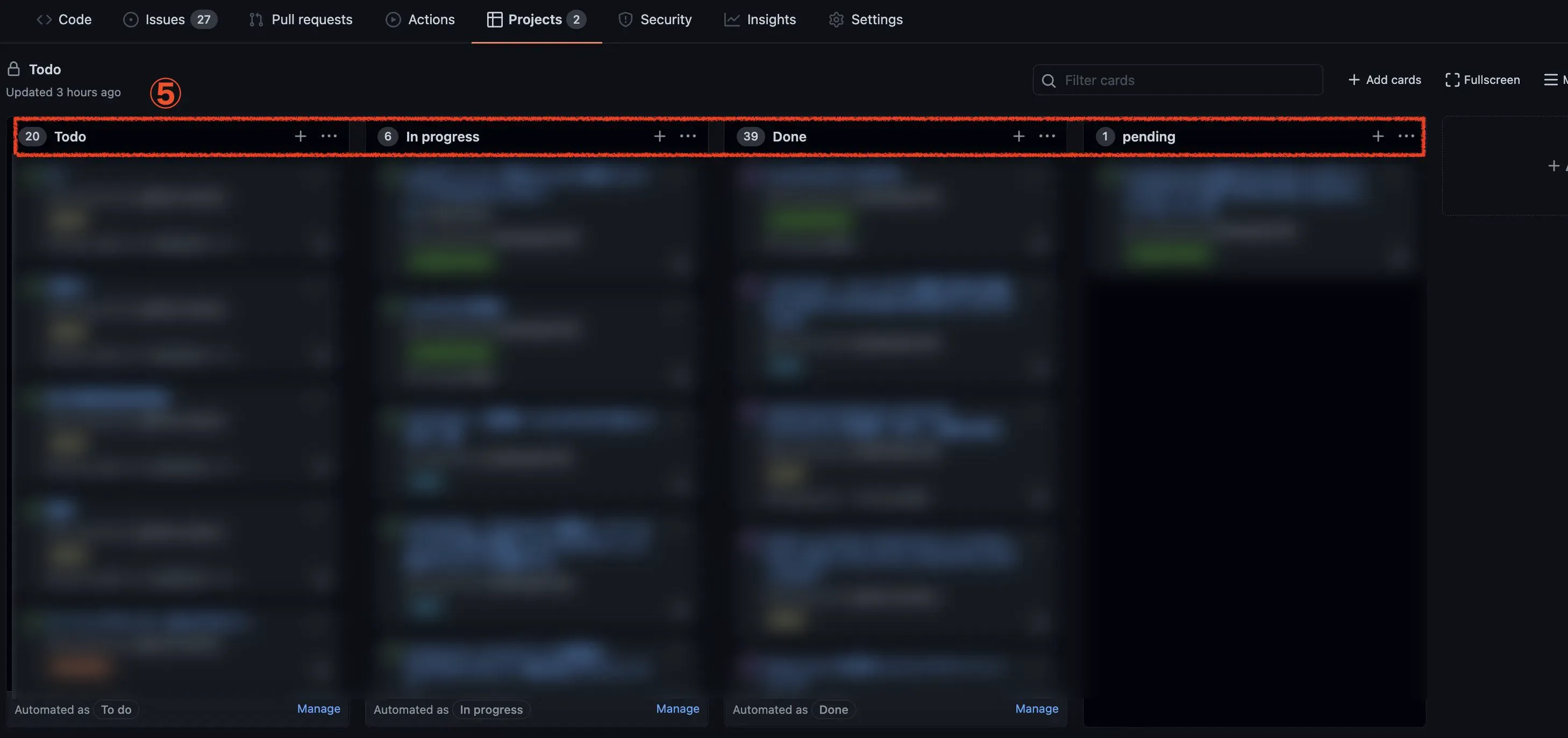
これがProjectのページ。
これがMarkdownテンプレートがある画面になります。
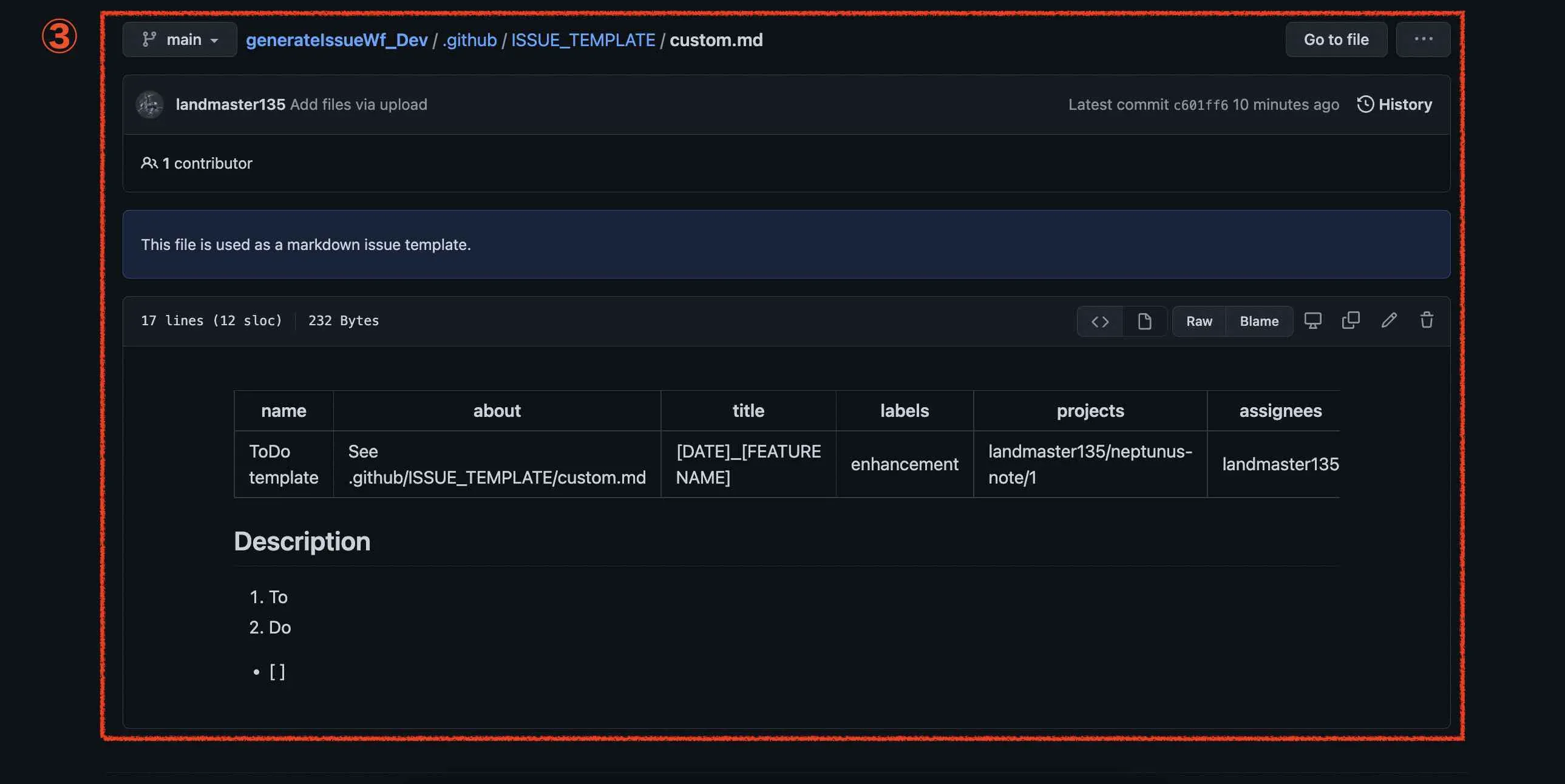
そのIssueなどのオプションに対して、このように設定しています。
| No | オプション | 説明 |
|---|---|---|
| 1 | title | Issuesのタイトルです。今回は、CSVのtitleフィールドの値を入れています。 |
| 2 | labels | ラベルです。デフォルトだと、「bug」とか「enhanced」とかあるやつです。今回は、「book」とか「blog」とかを指定しています。 |
| 3 | templates | Issues作成時に利用できるテンプレートMarkdownを指定します。ぶっちゃけ、登録する内容が毎回異なるので、指定はしていますが実際のところ使っていません。 |
| 4 | project | プロジェクト。IDで指定します。 |
| 5 | column | プロジェクトのkanbanのカラム。「To do」とか「Done」とか。(カラム名は空白文字が無いほうが良いです。結局設定の仕方が分かりませんでした。) |
| 6 | milestone | プロジェクトごとに設定できるマイルストーン |
| 7 | body | Issuesの内容(Description)です。 |
そして、色々設定したら、ワークフローファイルを書き出して、git pushします。
ワークフローファイル作成前のフォルダ構成は、こんな感じですが、
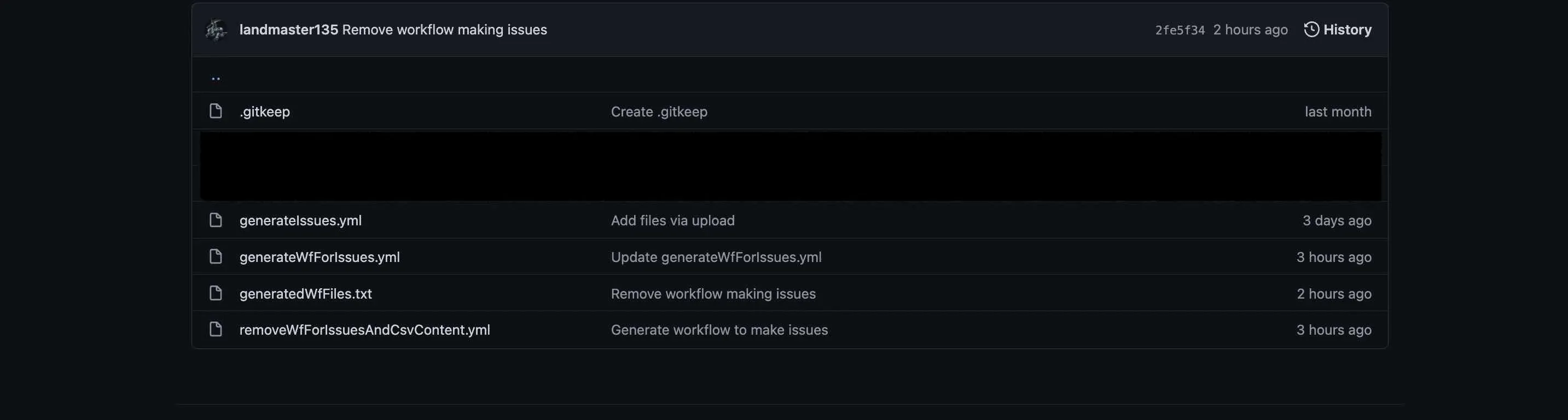
ワークフローファイル作成後は、こうなります。
以上で、generate_workflow_to_make_issue.pyの解説になります。
Pythonファイルその2:remove_workflow_files_making_issue.py
次に、ワークフローでIssuesが登録された後に行う処理の解説になります。
# Library by defaultfrom distutils.log import errorimport tracebackfrom pathlib import Pathimport os# Library by third party# nothing# Library in the local# nothing# Library in landmasterlibraryfrom landmasterlibrary.generaltool import get_src_path_from_test_path, read_txt_lines, get_files_by_extensions
def remove_workflow(): # remove workflow files. file_names_written_file_to_remove = ["generatedWfFiles.txt"] target_dir = ".github/workflows" file_names = read_txt_lines(__file__, file_names_written_file_to_remove, target_dir)[0] for i in range(0, len(file_names)): file_full_name = get_src_path_from_test_path(__file__, file_names[i], target_dir) os.remove(file_full_name) file_full_name_written_file_to_remove = get_src_path_from_test_path(__file__, file_names_written_file_to_remove[0], target_dir) with open(file_full_name_written_file_to_remove, "w") as fw: fw.write("")
# delete issue titles from csv files. extension = [".csv"] csv_files = get_files_by_extensions("./", extension) print(csv_files) for i in range(0, len(csv_files)): with open(csv_files[i], "r") as fr: read_lines = fr.readlines() print(read_lines) with open(csv_files[i], "w") as fw: fw.writelines(read_lines[0]) with open(csv_files[i], "r") as fr: read_lines = fr.readlines() print(read_lines)
def main(): remove_workflow()
if __name__ == "__main__": main()処理の流れとしては、
- Issuesを作成したワークフローファイルの名前の一覧が載っている
generatedWfFiles.txtを読み取る。 - 読み取ったファイル名のファイルを削除する。
generatedWfFiles.txtの内容を削除する。books.csvやblogs.csvに記載されているレコード部分の内容を削除する。
それでは、以下で詳しく解説していきます。
1.Issuesを作成したワークフローファイルの名前の一覧が載っている「generatedWfFiles.txt」を読み取る。
まず、Issuesを作成したワークフローファイルを削除します。
そのために、generatedWfFiles.txtに書いてあるファイル名を取得します。このファイルの内容は、実は先程、generate_workflow_to_make_issue.pyで記述していたのです。
例えば、このフォルダ構成になっている場合、
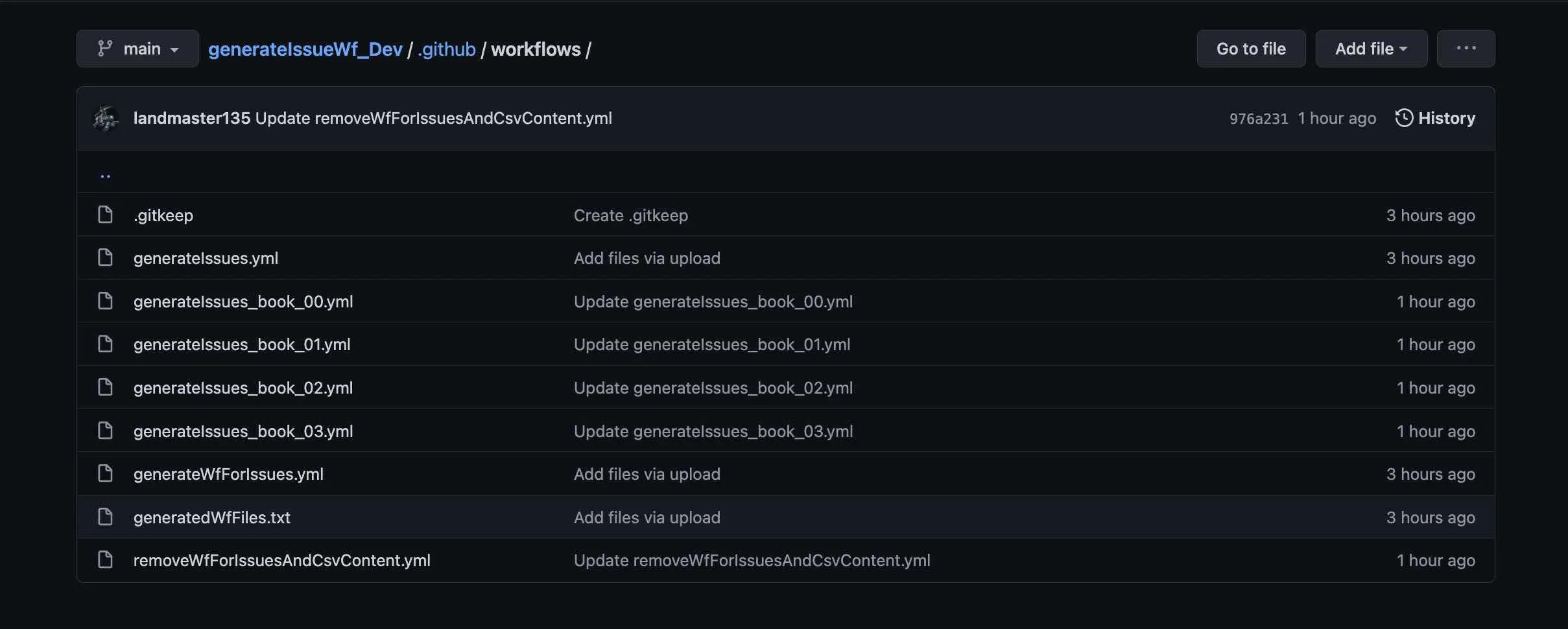
この内容が「generatedWfFiles.txt」に記載されています。
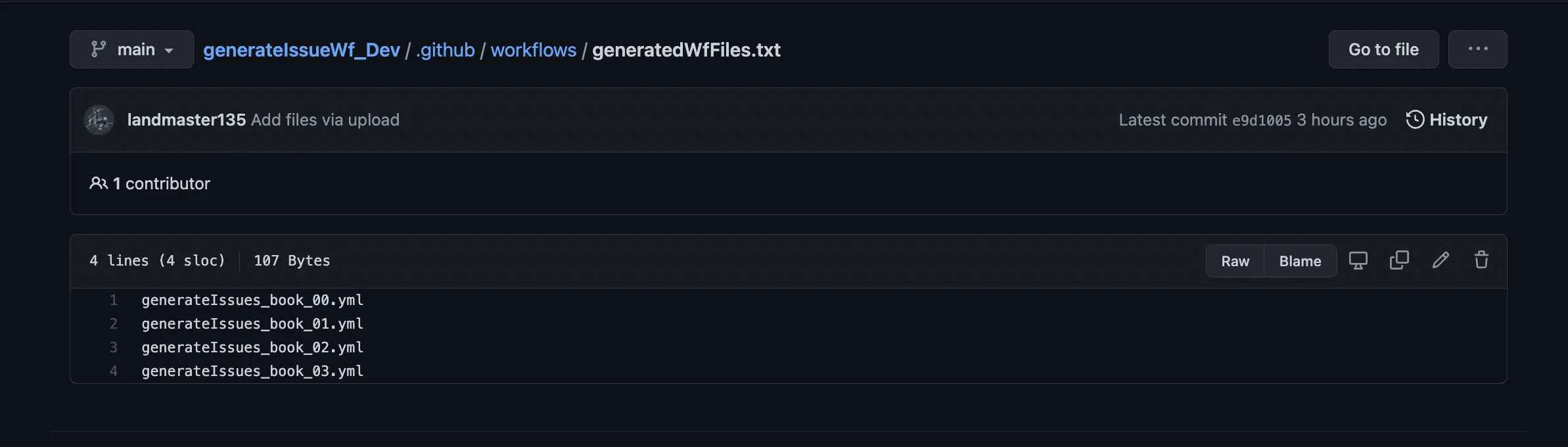
2.読み取ったファイル名のファイルを削除する。
そして、読み取ったファイルを元に、ファイルを削除します。
3.「generatedWfFiles.txt」の内容を削除する。
ファイルの削除が完了したら、generatedWfFiles.txtに記載されている内容を削除します。
4.「books.csv」や「blogs.csv」に記載されているレコード部分の内容を削除する。
CSVの内容を削除して、また同じタイトルのIssuesが登録されることに起こらないようにします。
以下のような状態になっているCSVに対して、
このようにヘッダー部が残るようにレコード部分だけ削除します。
そして、色々設定したら、編集もしくは削除したファイルに対してgit pushします。
以上で、remove_workflow_files_making_issue.pyの解説になります。
おしまい
以上になります!
記事を共有
この記事が役に立ったなら、ぜひ他の人と共有してください!
音楽
再生中なし